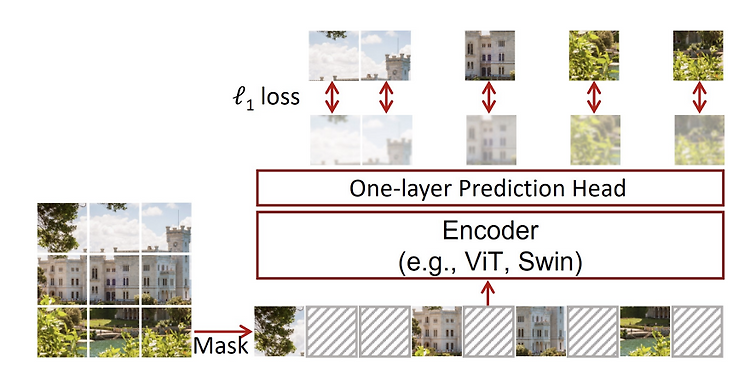
(23.05.21) SSL(self-supervised learning) 논문 리뷰 11탄 - 논문 제목: SimMIM: a Simple Framework for Masked Image Modeling (CVPR 2022) - https://arxiv.org/pdf/2111.09886v2.pdf - https://github.com/microsoft/SimMIM Abstract 본 논문은 SimMIM (a simple framework for masked image modeling) 을 제안한다. discrete VAE 혹은 clustering을 통한 block-wise masking과 tokenization 없이 간단하게 접근하였다. 저자가 제안하는 framework의 간단한 디자인은 매우 강력한 re..

(23.05.19) SSL (Self-supervised learning) 논문 리뷰 10탄 - contrastive learning (CL)과 maksed image modeling (MIM) 에 대해 비교하는 논문이다. - 논문 제목: What Do self-Supervised Vision Transformers Learn? (ICLR 2023) - https://arxiv.org/pdf/2305.00729.pdf Summary contrastive learning (CL) 과 masked image modeling (MIM) 의 representations, downstream tasks에서의 성능을 비교하는 논문이다. self-supervised ViT가 3가지 특성을 가진다는 것을 보여준다. (..
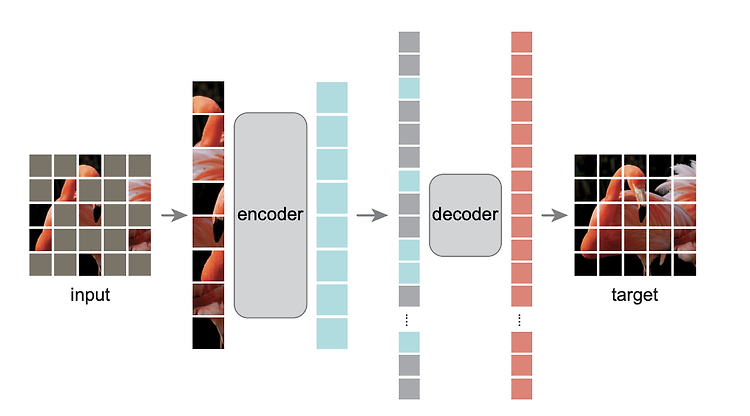
(23.05.18) SSL(self-supervised learning) 논문 리뷰 9탄 이것도 Kaiming He의 논문이다. 간단하게 정리해보았다. - 논문 제목: Masked Autoencoders Are Scalable Vision Learners (CVPR 2022) - https://arxiv.org/pdf/2111.06377.pdf - https://github.com/facebookresearch/mae Abstract 본 논문은 masked autoencoders 가 computer vision에서 scalable self-supervised learners라는 것을 보여준다. MAE approach는 간단하다. ==> input image의 random patches에 mask를 씌우고..
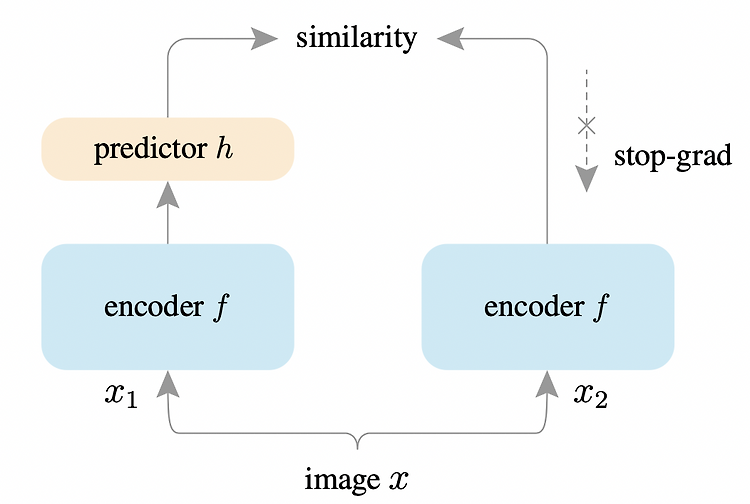
(23.05.04) SSL(self-supervised learning) 논문 리뷰 8탄 Kaiming He 의 논문이다 - 논문 제목: Exploring Simple Siamese Representation Learning (CVPR 2021) - https://arxiv.org/pdf/2011.10566.pdf Abstract Siamese networks는 unsupervised visual representation learning의 최신 모델에서 널리 쓰이고 있다. 하나의 image에 대한 두가지 augmentations 사이의 similarity를 최대화한다. 본 논문에서는 세가지 요소를 없앤 simple Siamese networks를 제안한다. 그 세가지 요소는 아래와 같다. 1. nega..

(23.05.03) Depth Estimation 논문 정리하기 4탄 이런 방법도 있구나.. 라는 것만 보고 넘어간다 - 논문 제목: Single-Image Depth Perception in the Wild (NeurIPS 2016) - https://arxiv.org/pdf/1604.03901v2.pdf (https://arxiv.org/pdf/2003.06620.pdf survey에서 설명하는 내용) supervised signal로 depth의 gorund truth가 사용되는 것이 아니라, realative depth annotations에 의해 학습된다. Abstract 본 논문에서는 unconstrained setting에서 single image로부터 depth를 회복하는 방식을 제안하며,..

(23.05.03) Depth Estimation 논문 정리하기 3탄 - 논문 제목: Deeper Depth Prediction with Fully Convolutional Residual Networks (3DV 2016) - https://arxiv.org/pdf/1606.00373v2.pdf (https://arxiv.org/pdf/2003.06620.pdf survey에서 설명하는 내용) depth maps와 single images들 간의 relation을 매핑하는 것을 학습하기 위해서 residual learning을 도입한 논문이다. Summary 제안한 방식은 기존의 것보다 단순하지 않다. 그러나, 더 적은 data와 더 적은 time에 더 높은 퀄리티의 결과를 달성했다는 점에서 의미가 있..

(23.05.02) Depth Estimation 논문 정리하기 2탄 - 논문 제목: Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture (ICCV 2015) - https://arxiv.org/pdf/1411.4734v4.pdf (https://arxiv.org/pdf/2003.06620.pdf survey에서 설명하는 내용) single image로부터 depth estimation, surface normal estimation, semantic label prediction과 같은 task를 다룰 수 있는 일반적인 multi-scale framework를 제안..

(23.05.01) Depth Estimation 논문 정리하기 1탄 - 논문 제목: Depth Map Prediction from a Single Image using a Multi-Scale Deep Network (NeurIPS 2014) - https://arxiv.org/pdf/1406.2283v1.pdf (https://arxiv.org/pdf/2003.06620.pdf survey에서 설명하는 내용) supervised methods의 supervisory signal은 depth maps의 ground truth에 기반한다. Monocular depth estimation은 regressive problem으로 여겨질 수 있다. deep neural network는 single images..

(23.04.03) Vision Language Model 논문 리뷰 1탄 논문 제목: Learning Transferable Visual Models From Natural Language Supervision (2021) - https://arxiv.org/pdf/2103.00020.pdf 기존 state-of-art computer vision systems - 고정되어있는 object 카테고리에서 예측하고 학습. -> 제한되어있는 supervision 형태로 인해 제한되는 부분들 발생. -> 자연어를 사용하여 image representation learning하는 것은 어떨까? ====> natural language supervision CLIP 1) contrastive pre-trainin..

(23.03.14) weakly + semi 합해서 segmentation 하는 방법론 떠오르는게 있어서 정리해두고, 비슷한 논문이 있는지 찾아봤는데 역시나 이미 논문이 있다.. semi, weakly 선행 연구에 대해서 논문에 잘 설명되어있어서 내용 정리하는 느낌으로 적어보았다. 논문에서 제안하는 방법론의 그림과 글의 내용이 뭔가 맞지 않아서 이해한게 맞는지 모르겠다.. 논문 제목: Learning pseudo labels for semi-and-weakly supervised semantic segmentation - https://www.sciencedirect.com/science/article/pii/S003132032200406X 우선, segmentation에서 사용되는 semi-superv..

(2023.03.04) semantic segmentation 논문 리뷰 2탄 - 논문 제목: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation (2015) - https://arxiv.org/pdf/1511.00561v3.pdf Model Architecture SegNet은 encoder-decoder 구조이다. - encoder는 vgg16의 13 conv layer를 가져왔다. (fully connected layer는 resolution을 낮추고 parameter가 늘어나기 때문에 없앴다.) - 이와 대응하는 decoder도 13 layer로 구성되어있다. - 마지막 decoder의 output은 multi-clas..

(23.03.02) Semantic segmentation 논문 리뷰 1탄 - 논문 제목: Fully Convolutional Networks for Semantic Segmentation (CVPR 2015) - https://arxiv.org/pdf/1411.4038.pdf Summary FCN은 convolutional network 구조로 end-to-end 학습이 가능하며, pixel 단위로 class를 예측하는 semantic segmentation 분야에서 이 당시 SOTA를 달성했다. Keyword - end-to-end convolutional network for semantic segmentation (최초?) - 기존 pre-training model (AlexNet, VGG 등)을..

(23.02.14) WSL(weakly supervised learning) 논문 리뷰 3탄 본 논문에서 제안하는 method가 연관 개념들이 굉장히 많이 들어간다. 성능개선이 있었지만, 간단한 mechanism은 아닌듯하다...! - 논문 제목: Self-supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation (CVPR 2020) - https://arxiv.org/pdf/2004.04581v1.pdf 핵심 정리 - SEAM, PCM 제안. fully and weakly supervision의 gap을 줄이고자. - siamese network 구조로 구현, ECR(equivariant cross reg..

(23.02.12) WSL(weakly supervised learning) 논문 리뷰 2탄 사전지식이 별로 없는 상태에서 읽어서 이해하는데 조금 시간이 걸렸다. 논문 읽는 것에서 끝나지 않고, 코드를 봐야한다는 생각이 강력하게 드는 논문이다. - 논문 제목: Weakly-Supervised Semantic Segmentation Network with Deep Seeded Region Growing (CVPR 2018) -https://openaccess.thecvf.com/content_cvpr_2018/papers/Huang_Weakly-Supervised_Semantic_Segmentation_CVPR_2018_paper.pdf Weakly-supervised semantic segmentatio..

(23.02.09) WSL(weakly supervised learning) 논문 리뷰 1탄 CAM을 읽어보았다...! 꽤나 오래된 논문이지만, 아직도 꾸준히 인용되고 있다. - 논문 제목: Learning Deep Features for Discriminative Localization (CVPR 2016) - https://arxiv.org/pdf/1512.04150v1.pdf Problem & Solution Problem - CNN이 좋은 성능을 내는데, 이것이 왜 좋은 성능을 내는지 쉽게 설명할 수 없다는 black-box 문제가 있다. Solution - CAM을 제안하여 CNN이 어떻게 task를 수행하는지 설명할 수 있게 된다. -> 즉, CNN이 어떤 부분을 보고 예측했는지를 알려주는 역..