(23.03.14)
weakly + semi 합해서 segmentation 하는 방법론 떠오르는게 있어서 정리해두고, 비슷한 논문이 있는지 찾아봤는데
역시나 이미 논문이 있다..
semi, weakly 선행 연구에 대해서 논문에 잘 설명되어있어서 내용 정리하는 느낌으로 적어보았다.
논문에서 제안하는 방법론의 그림과 글의 내용이 뭔가 맞지 않아서 이해한게 맞는지 모르겠다..
논문 제목: Learning pseudo labels for semi-and-weakly supervised semantic segmentation
- https://www.sciencedirect.com/science/article/pii/S003132032200406X
우선, segmentation에서 사용되는 semi-supervised learning과 weakly-supervised learning에 대해 전체적으로 정리해본다.
Semi-supervised learning
: small cluster of labeled data + massice unlabeled data 로 model을 학습시키는 것이다.
아래와 같은 로드맵으로 진행된다.
1. labeled data에 대해 augmentation
2. unlabeled data로 self-supervision exploration
3. labeled set -> unlabeled set으로 knowledge transforamtion
1 -> mixup, cutmix 등이 있다.
2 -> contrastive learning으로 model을 pre-train 하거나 (image-level or pixel-level) / semi-supervised learning 진행하는 동안 consistencty regularization (ex. UDA)
3 -> self-training strategy
(labeled set으로 학습하고, unlabeled set으로 pseudo labels 생성)
(co-training, mean-teacher, multi-teacher)
WSSS (Weakly supervised semantic segmentation)
: image-level label을 가지고서, segmentation(pixel-level-classification)을 하는 것이다.
WSSS는 주로 CAM을 기반으로 해서, seed regions select 하는 SEC pipeline을 사용하는 추세이다.
(IRNET, SEAM 등등)
SWSSS
semi + weakly supervised semantic segmentation ====> SWSSS
기존의 SWSSS 방법론 roadmap
1. limited strong annotations + massice weak annotations -> strongly labeled data에 overfits될 가능성있음
2. applying WSSS methods directly (based on CAM), only learned by image-level label) -> CAM-style pseudo lables는 부정확함
3. focus on segmentation model design -> 부정확한 pseudo labels로 model degeneration 발생
pseudo labels prediction을 improving하여 SWSSS를 해결해보자!!
(few pixel-level labeled data + massive image-level labeled data)
본 논문에서 제안하는 방법론의 road map
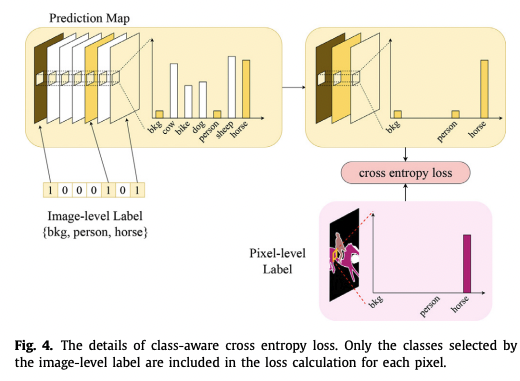
1. image-level labels의 도움을 받아 class-aware cross entropy(CCE) loss 제안
pixel-level에 overfitting되는 것을 막고자.
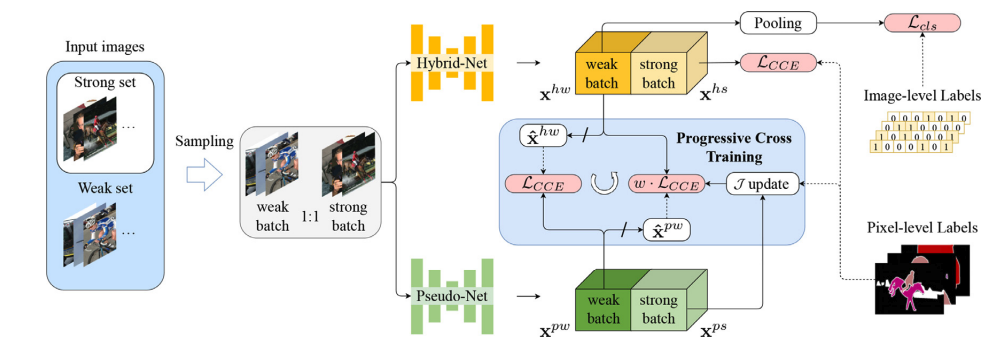
2. progresssive cross training (PCT) method 제안
-----> hybrid-Net + pseudo-Net 으로 구성되는데, 이 둘은 구조는 같지만, weights를 공유하지는 않는다.
두 network의 input batches는 동일하다.
hybrid-Net을 먼저 보면, hybrid supervision으로 학습한다. hybrid supervision은 pixel-level labels와 image-level labels 이다.
- strongly (pixel-level) labeled data에 대해서는 ground truth와 비교하여 CCE loss(segmentation loss)에 의해 supervised 학습한다. (segmentation loss)
- weakly (image-level) labeled data에 대해서는 hybrid-Net prediction이 max-pooling layer를 거쳐서 cls loss (multi-label classificaion loss) 에 의해 supervised 학습한다.
-> pixel-level supervision이 있긴하지만, 더 많은 pixel-level supervision이 필요하다!!
pseudo-Net은 hybrid-Net의 predictions가 pseudo labels로 사용된다.
(hybrid's predictions는 image-level labels masking 되었다가 one-hot 형태의 pseudo labels가 된다)
- pseudo-Net의 predictions 중에서 좋은 predictions를 찾기 위해서 dynamic evaluation 을 제안한다. pseudo-Net에서는 strongly (pixel-level) labeled data에 대해서 hybrd-Net's predictions(pseudo labels)과 비교하여 CCE loss로 supervised 학습한다. 그렇기 때문에 strongly labeled data의 ground truth는 pseudo-Net을 mIoU로 evaluate하기 위해 사용된다. dynamic evaluation 을 통해서 J 를 업데이트한다. (momentum update 방식 적용) J는 P2H training에서 사용된다.
- weakly (image-level) labeled data에 대해서는 hybrid-Net's predictions(pseudo labels)과 비교하여 CCE loss에 의해 supervised 학습한다. => H2P training (hybrid-to-pseudo)
그리고 여기서 다시, hybrid-Net는 weakly labeled data에 대해서 pseudo-Net's predictions인 x^_pw와 비교하여 CCE loss로 supervised 학습한다. CCE loss에 w가 곱해지는데, w는 dynamic evaluation을 통해 업데이트한 J를 사용하여 계산해준다. => P2H training (pseudo-to-hybrid)
3. 최종 hybrid-Net predictions를 downstream의 retraining step으로 가져간다. 이 pseudo lables로 fully supervised 학습한다!!!
(관련 식은 논문에~~)

