(23.03.02)
Semantic segmentation 논문 리뷰 1탄
- 논문 제목: Fully Convolutional Networks for Semantic Segmentation (CVPR 2015)
- https://arxiv.org/pdf/1411.4038.pdf
1. Summary
FCN은 convolutional network 구조로 end-to-end 학습이 가능하며, pixel 단위로 class를 예측하는 semantic segmentation 분야에서 이 당시 SOTA를 달성했다.
2. Keyword
- end-to-end convolutional network for semantic segmentation (최초?)
- 기존 pre-training model (AlexNet, VGG 등)을 fine-tuning하여 사용
- input resolution == output resolution (by upsampling)
- skip architecture 사용
3. Method

figure 2 그림에서 위쪽 네트워크 아키텍쳐가 기존의 cnn classification network들인데, 아키텍쳐 마지막 부분에 fully connected layer가 들어가 있다. fc layer는 공간정보를 담아내지 못해서 segmentation 에서 좋지 못하다. FCN 논문에서는 이를 개선하고자 fc layer 대신에 1x1 conv layer로 대체하여 공간정보를 유지할 수 있도록 했다. 마지막 layer까지 거쳐서 나온 feature map의 channel 수는 예측하고자 하는 class의 수와 같다는 게 핵심이다.
<FCN architecture>
1단계) convolution layer로 feature 뽑아낸다 (classification CNN의 conv layer)
2단계) 1x1 convolution layer로 feature map을 뽑아낸다 (=class presence heat map)
3단계) upsampling하여 input과 동일한 resolution의 prediction map을 생성한다
4단계) prediction map의 각 pixel class에 맞게 색칠하여 segmentation map을 생성한다
1, 2단계: downsampling -> feature map (heat map) 추출한다
3단계: upsampling -> feature map를 original input image의 resolution(size)로 맞춰준다
4단계: upsampling된 prediction map은 class개수만큼의 channel개수를 가진다. argmax를 통해서 pixel당 class를 예측하여 최종 segmentation map을 반환한다.
그런데, 여기서 upsampling하면 디테일하지 못한 segmentation이 나온다. FCN 논문에서는 이를 해결하기 위해서 skip combining기법을 사용한다.
FCN-32s가 기본 네트워크이고, FCN-16s, FCN-8s이 skip combining을 적용한 것이다.
(아래 두 그림의 출처: https://wooono.tistory.com/267)
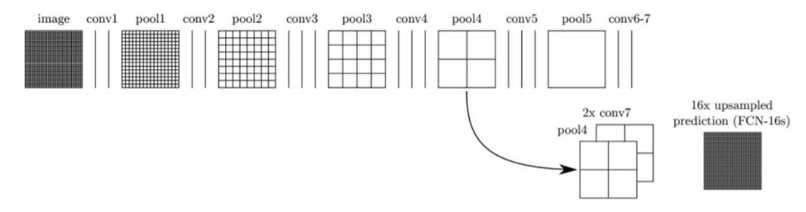
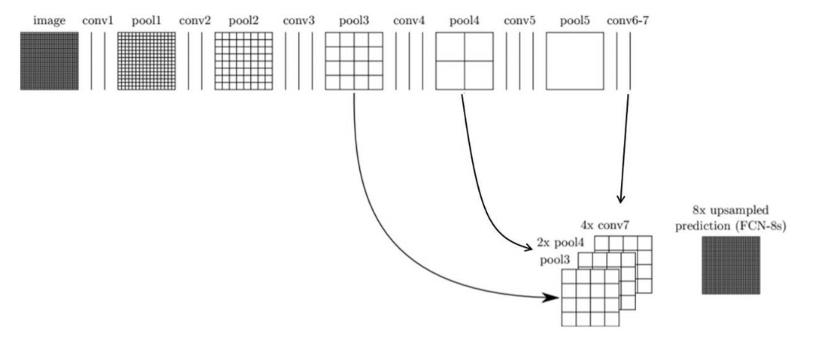

FCN 논문에서는 skip combining 방식을 사용한 것이 예측을 더 잘한다는 것을 실험으로 보여주었다.
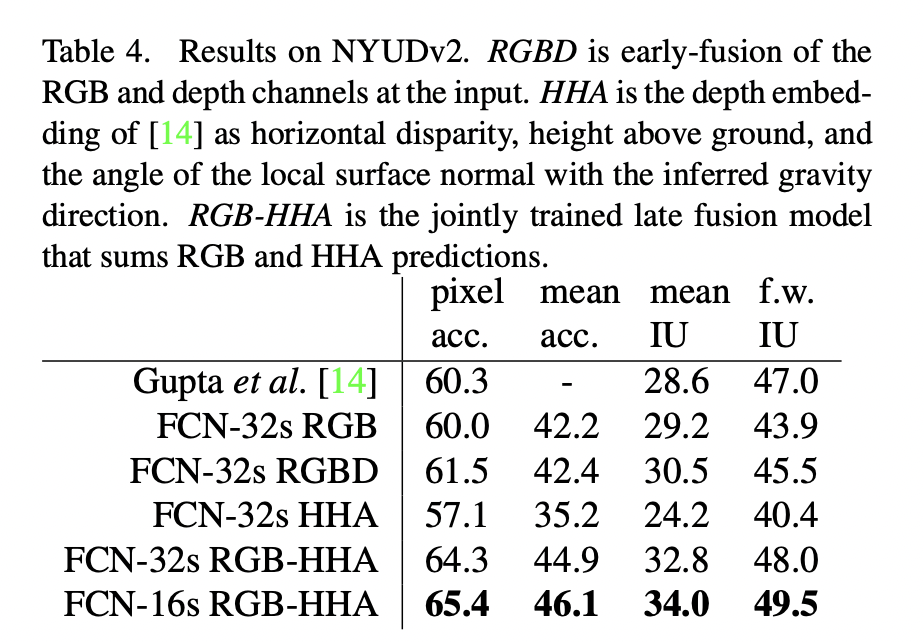
4. Experiment