(23.04.03)
Vision Language Model 논문 리뷰 1탄
논문 제목: Learning Transferable Visual Models From Natural Language Supervision (2021)
- https://arxiv.org/pdf/2103.00020.pdf
기존 state-of-art computer vision systems
- 고정되어있는 object 카테고리에서 예측하고 학습.
-> 제한되어있는 supervision 형태로 인해 제한되는 부분들 발생.
-> 자연어를 사용하여 image representation learning하는 것은 어떨까?
====> natural language supervision
CLIP
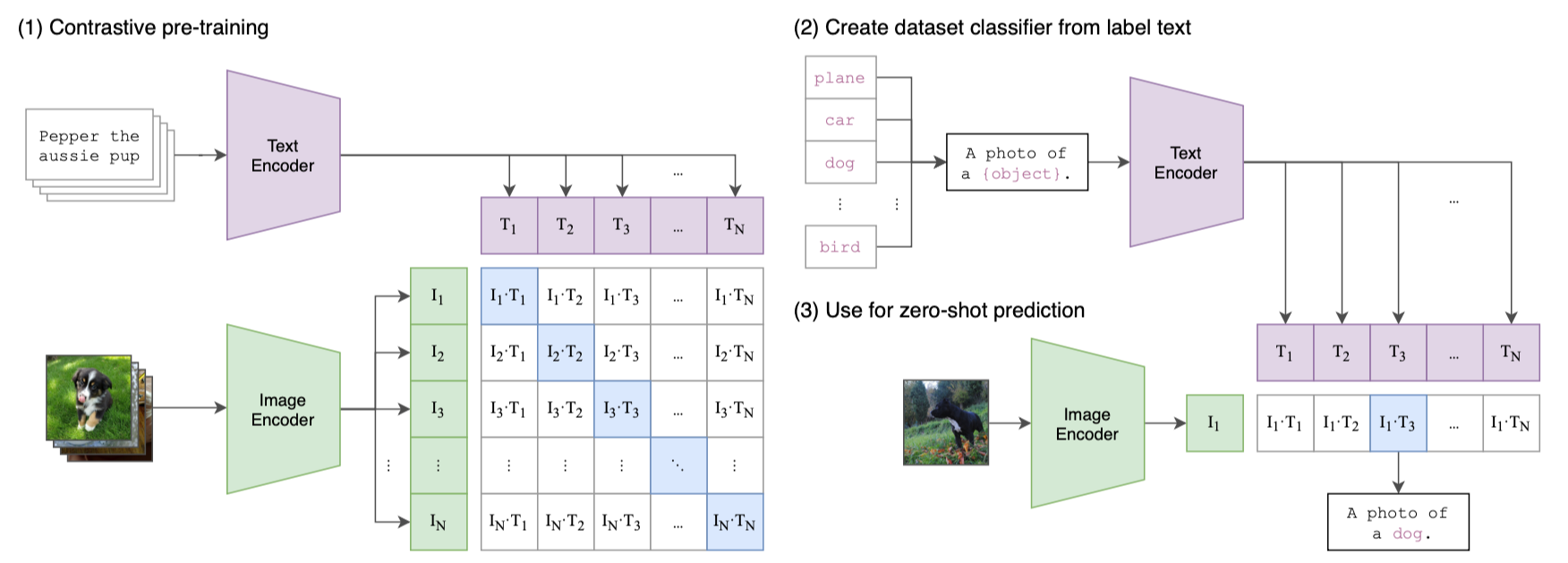
1) contrastive pre-training
- 기존의 image model들은 image feature extractor와 linear classifier를 학습시켜 label을 예측하는 방식이었다.
- CLIP은 image encoder와 text encoder를 사용하여 (image, text) training images(N batch)에 대해 학습하고, correct pairing (NxN)을 예측한다.
- image encoder와 text encoder에서 나온 2개의 embedding 값에 대해 contrastive learning을 한다.
- 2개 embedding 의 유사도(cosine similarity) 를 계산하여 (NxN)테이블에서의 대각선은 cosine similarity가 커지게끔, 그 외의 요소는 cosine similarity가 작아지게끔 학습시킨다. => CLIP이 multi-modal embedding space를 학습함.
- image encoder -> ResNet-50 (global average pooling -> attention pooling)
- text encoder -> Transformer


2) create dataset classifier from label text
- 예측 class 값이 될 수 있는 여러 text label 에 대해 text encoder에 넣어 text embedding 을 만들어낸다.
3) use for zero-shot prediction
- image를 image encoder에 넣어 image embedding으로 만들고, 2)에서 만들었던 text embedding와의 유사도를 비교하여 가장 유사한 text label을 찾는다.
- 이때, unseen class에 대해서 예측할 수 있다 -> zero-shot transfer
Natural Language Supervision
- 언어에 대한 representation도 학습하기 때문에 zero-shot transfer 가능.
- 라벨링 필요하지 않아 scaling 용이함.
Large Dataset
- MS-COCO, Visual Genome, YFCC100M 세가지 데이터셋에서 image들을 natural language titles 혹은 descriptions (in English) 파일 이름을 갖도록 하였다.
- 이 크기는 ImageNet과 같았다.
Experiments


