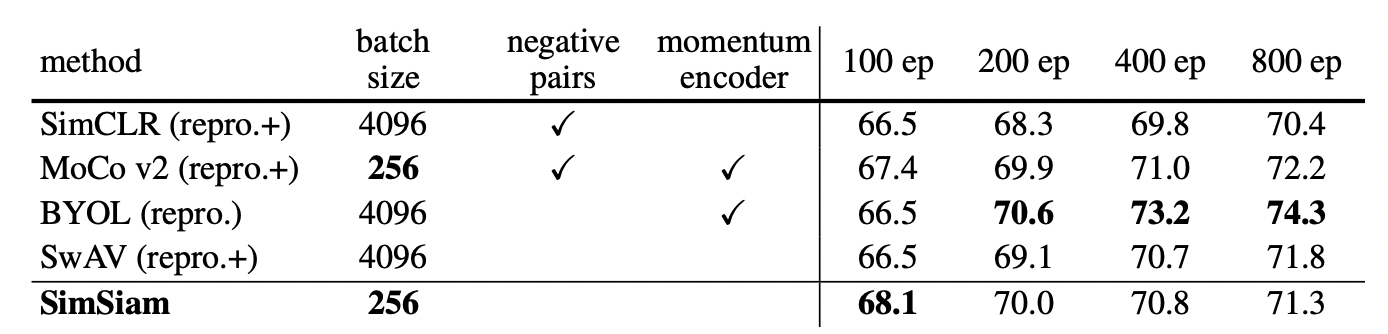
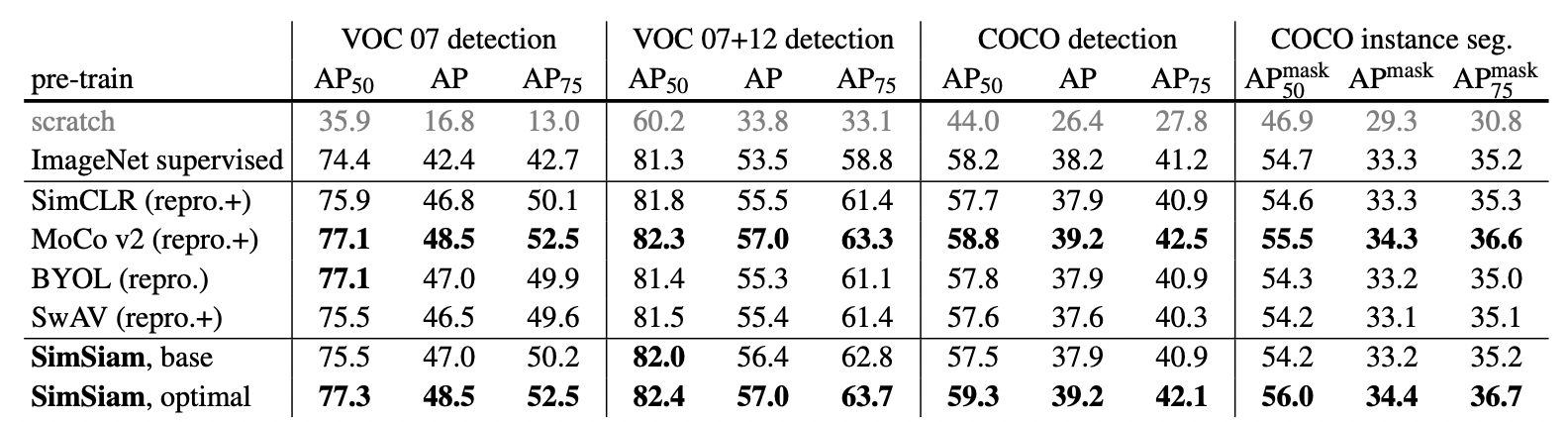
(23.05.04)
SSL(self-supervised learning) 논문 리뷰 8탄
Kaiming He 의 논문이다
- 논문 제목: Exploring Simple Siamese Representation Learning (CVPR 2021)
- https://arxiv.org/pdf/2011.10566.pdf
1. Abstract
Siamese networks는 unsupervised visual representation learning의 최신 모델에서 널리 쓰이고 있다.
하나의 image에 대한 두가지 augmentations 사이의 similarity를 최대화한다.
본 논문에서는 세가지 요소를 없앤 simple Siamese networks를 제안한다. 그 세가지 요소는 아래와 같다.
1. negative sample pairs
2. large batches
3. momentum encoders
collapsing solutions을 막고자 stop-gradient 을 적용하였다.
본 논문에서 제안하는 메소드의 이름은 SimSiam 으로 unsupervised representation learning의 Siamses 아키텍쳐의 역할에 대해 다시생각하게 하는 그런 간단한 baseline이다 !
2. Method

SimSiam 은 아키텍처 자체도 매우 간단하다!!
[SimSiam의 진행과정]
- 하나의 이미지에 대해서 2가지의 augmentation을 적용시켜준다. (x1, x2)
- 동일한 encoder network (f) 에 넣어준다. (encoder network == backbone + projection MLP)
- 한쪽에만 prediction MLP (h)를 적용한다. (p1, z2)
- 다른 한쪽은 stop-gradient operation이 적용된다.
- 둘 사이의 similarity를 최대화하는 방향으로 학습을 진행해준다.
=> 이 방식은 negative pairs가 필요없으며, momentum encoder 또한 필요하지 않다.
default backbone으로는 ResNet-50을 사용하였다.
3. Loss function
[negative cosine similarity]
negative cosine similarity를 loss function으로 사용하며, 이를 최소화하는 방향으로 학습한다.
이는 l2-normalized vectors의 mean squared error와 동일하다.
[symmetrized loss]
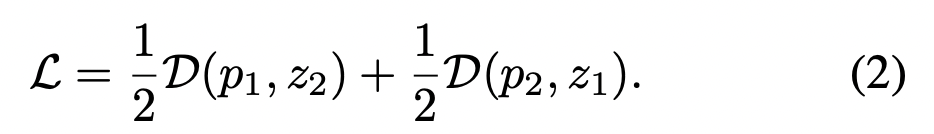
각 image마다 정의되는데, total loss는 모든 image에 대한 평균이다. minimum possible value는 -1이다.
[stop-gradient operation]이 적용된 경우에는 아래의 식으로 적용된다.
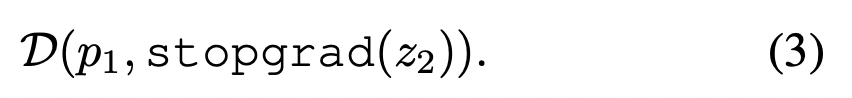
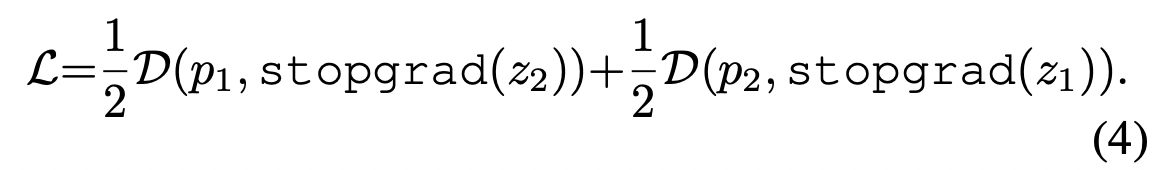
첫 term에서 x2에 대한 encoder는 z2로부터 gradient를 받지 못하지만, 두번째 term에는 p2로부터 gradient를 받는다.
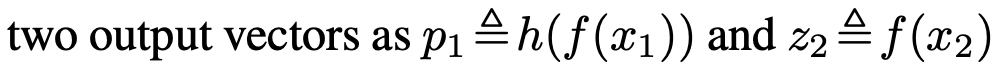
4. SimSiam pseudocode

5. Experiments