
(23.05.18)
SSL(self-supervised learning) 논문 리뷰 9탄
이것도 Kaiming He의 논문이다. 간단하게 정리해보았다.
- 논문 제목: Masked Autoencoders Are Scalable Vision Learners (CVPR 2022)
- https://arxiv.org/pdf/2111.06377.pdf
- https://github.com/facebookresearch/mae
1. Abstract
본 논문은 masked autoencoders 가 computer vision에서 scalable self-supervised learners라는 것을 보여준다.
MAE approach는 간단하다.
==> input image의 random patches에 mask를 씌우고, missing pixels에 대해 reconstruct한다.
MAE의 2가지 core design
1. asymmetric encoder-decoder architecture
- encoder는 mask token 없는 visible patch들만 연산한다.
- decoder는 latent representation과 mask token으로부터 original image를 reconstruct한다.
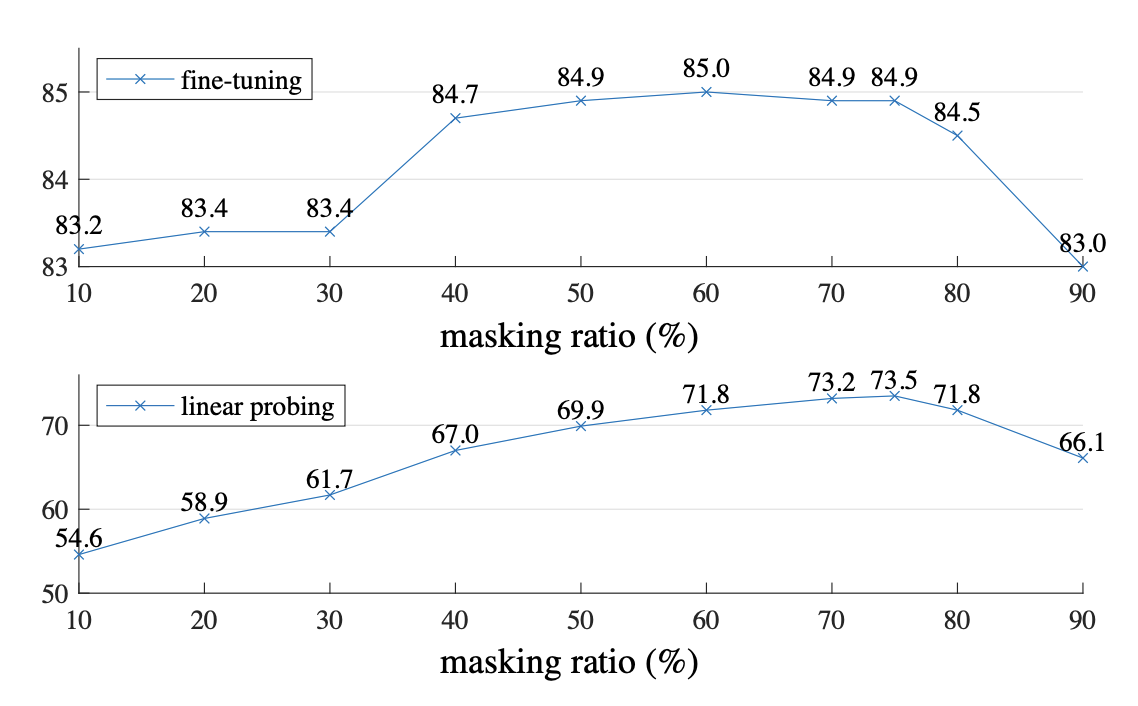
2. input image에 대한 masking 비율이 높을수록(75%) nontrivial & meaningful self-supervisory task를 만든다는 것을 찾았다.
==> 이 두가지는 large models를 효율적이고 효과적으로 학습할 수 있도록 했다.
==> downstream tasks 에 대한 transger 성능에 대해서 supervised pretraiing보다 높은 성능을 보였다.
2. Method

asymmetric design
- encoder: mask tokens 없이 operate
- decoder: latent representation과 mask token 으로부터 full signal을 reconstruct
masking
- image를 non-overlapping patches 로 나누어준다.
- 정규분포에 따라 replacement없이 random patches를 추출한다.(==random sampling)
- high masking ratio로 random sapmling하여 의존성을 줄여주어 efficient encoder를 만들 수 있도록 한다.
MAE encoder
- ViT 사용. visible, unmasked patches들만 적용한다.
- positinal embedding 추가하여 linear projection 을 통해 patch들을 임베딩하고, transformer blocks를 통해서 과정 진행한다.
- full set의 25%만 사용하기 때문에 (masked patches 제거하니까) compute and memory를 조금만 사용한다.
MAE decoder
- encoded visible patches와 mask tokens 로 구성된 full set이 MAE decoder의 input으로 들어온다.
- 모든 token에다가 positional embedding을 추가한다. (이게 없으면 mask token이 image에서 어떤 위치에 있는지에 대한 정보가 없다)
- image reconsturction task를 수행하기 위한 pre-training에만 사용된다. (down stream task에서 사용되지 않음)
Reconstruction target
- MAE는 각 masked patch에 대한 pixel 값을 예측하여 reconsturct한다.
- decoder의 출력값에 있는 각 요소는 patch를 표현하는 pixel 값의 벡터이다.
- decoder의 마지막 층은 linear projection이다. (ouput channel의 수 == patch에서 pixel 값의 수)
- loss function: MSE (mean squared error), masked patches에 대해서만 loss 계산한다.
- 모든 pixel에 대한 mean, standard deviation을 계산하여 각 mased path에 normalize한다.
Simple implementation
- 모든 input patch에 대해 token을 생성한다. (positional embedding을 더하여 linear projection)
- token list를 랜덤하게 shuffle하고, masking ratio를 따라 token list의 마지막 부분을 제거한다.
- 이 과정으로 완성된 small subset을 encoder에 넣는다.
- encoded patche의 list에다가 masked token을 추가하고 이 full list를 unshuffle하여 모든 token을 target과 정렬한다.
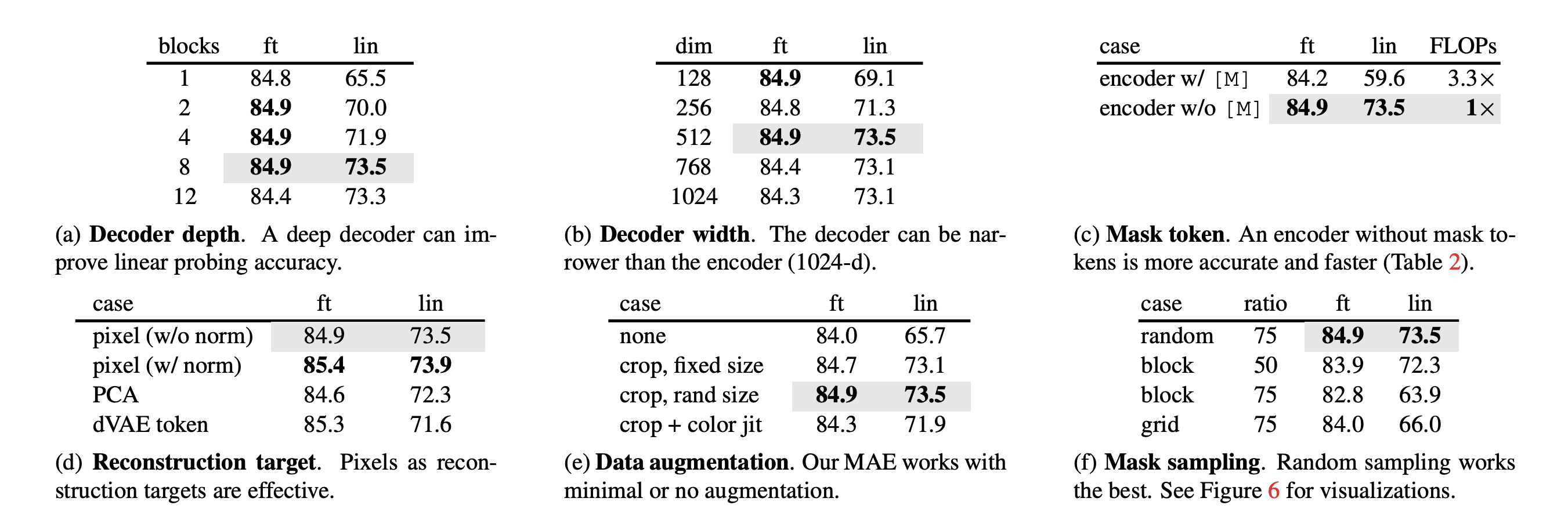
3. Experiment
'Computer Vision > 논문' 카테고리의 다른 글
| [simMIM] SimMIM: a Simple Framework for Masked Image Modeling (0) | 2023.05.21 |
|---|---|
| What Do Self-supervised Vision Transformers Learn? (1) | 2023.05.19 |
| [SimSiam] Exploring Simple Siamese Representation Learning (1) | 2023.05.04 |
| [논문] Single-Image Depth Perception in the Wild (0) | 2023.05.03 |
| [논문] Deeper Depth Prediction with Fully Convolutional Residual Networks (0) | 2023.05.03 |
