(23.05.21)
SSL(self-supervised learning) 논문 리뷰 11탄
- 논문 제목: SimMIM: a Simple Framework for Masked Image Modeling (CVPR 2022)
- https://arxiv.org/pdf/2111.09886v2.pdf
- https://github.com/microsoft/SimMIM
Abstract
본 논문은 SimMIM (a simple framework for masked image modeling) 을 제안한다.
discrete VAE 혹은 clustering을 통한 block-wise masking과 tokenization 없이 간단하게 접근하였다.
저자가 제안하는 framework의 간단한 디자인은 매우 강력한 representation learning performance를 보여준다.
1) 큰 masked patch size(32)로 random masking 하는 것이 강력한 pre-text task를 만들었다.
2) direct regression을 통해서 raw pixels의 RGB 값을 예측하는 것은 복잡한 디자인의 patch classification 보다 나쁘지 않다.
3) prediction head는 linear layer와 같은 가벼운 것이 무거운 것보다 나쁘지 않다.
Introduction
vision 과 language 간의 차이
1) image는 locality 가 조금 더 강하다. pixel들이 근처와 밀접하고 강하게 상관관계를 맺고 있다.
2) visual signals는 raw and low-level 이고, text tokens 는 human-generated high level이다.
3) visual signal 은 contiuous, text token 은 discrete
본 논문에서 제안하는 simple framework의 Key designs와 Insights
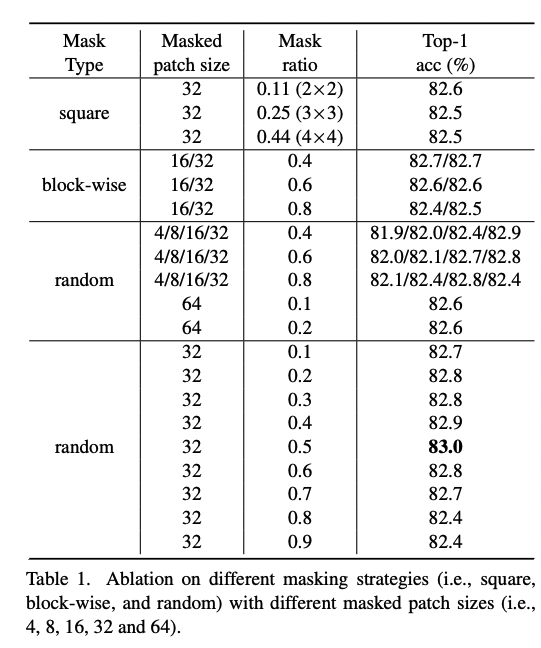
- random masking 은 image patch들에 적용된다. 32사이즈의 큰 masking patch로, 10~70%의 masking ratio에서 경쟁력있는 성능을 보였고, 8사이즈의 작은 masking patch에서는 80%의 masking ratio 가 되어야 좋은 성능이 나왔다.
- raw pixel regression task 가 사용되었다.
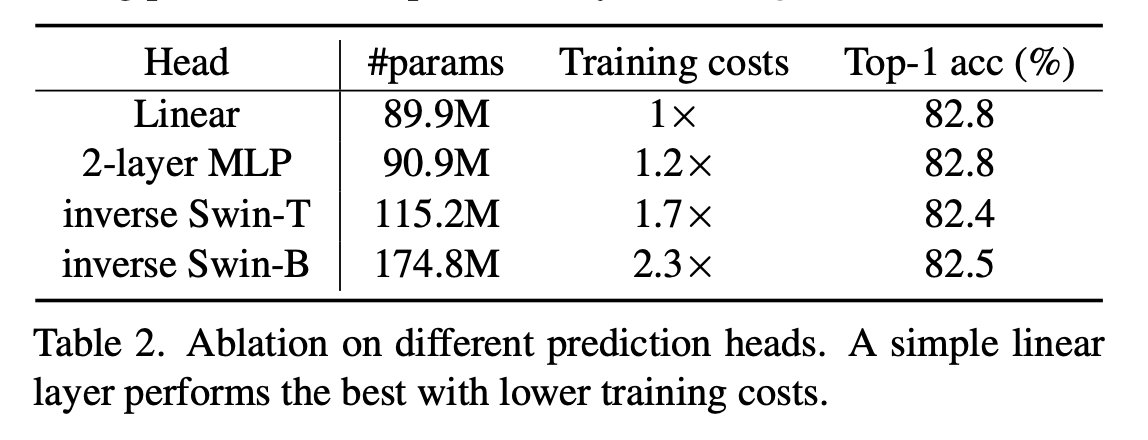
- lightweight prediction head 가 사용되었다. 이는 pre-training 에서 speedup을 가져온다.
Method

masking strategy
- input image에 대해서 masking할 영역을 어떻게 선택하는지에 대한 것으로, masking 이후의 transformed image가 input 으로 사용된다.
- masked patch 대신 learnable mask token vector로 대체하여 사용한다.
-> 1. patch-aligned random masking: patch-level 로 마스킹을 하는데, 이 patch 는 fully visible 또는 fully masked 되어있다. patch size 는 4x4 ~ 32x32 이다.
-> 2. other masking strategies: central region masking strategy, complex block-wise masking strategy

encoder architecture
- masked image에 대한 latent feature representation을 추출하는데, 이는 이후 masked area에 대한 original signals를 예측하는 데에 사용된다. 해당 encoder 는 다양한 vision task에 transferable 된다. 본 논문에서는 Vision Transformer 로 vanilla ViT 와 Swin Transformer를 사용한다.
prediction head
- prediction head 는 latent feature representation에 적용되어 masked area 에서 original signal를 만들어내는 역할을 한다.
prediction target
- 예측하고자하는 original signal의 형태로, cross-entropy classification loss와 l1, l2 regression loss를 포함하여 loss 로 정의된다.
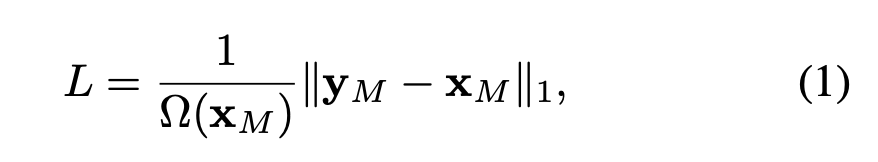
Experiment
'Computer Vision > 논문' 카테고리의 다른 글
| What Do Self-supervised Vision Transformers Learn? (1) | 2023.05.19 |
|---|---|
| [MAE] Masked Autoencoders Are Scalable Vision Learners (0) | 2023.05.18 |
| [SimSiam] Exploring Simple Siamese Representation Learning (1) | 2023.05.04 |
| [논문] Single-Image Depth Perception in the Wild (0) | 2023.05.03 |
| [논문] Deeper Depth Prediction with Fully Convolutional Residual Networks (0) | 2023.05.03 |
