(23.05.19)
SSL (Self-supervised learning) 논문 리뷰 10탄
- contrastive learning (CL)과 maksed image modeling (MIM) 에 대해 비교하는 논문이다.
- 논문 제목: What Do self-Supervised Vision Transformers Learn? (ICLR 2023)
- https://arxiv.org/pdf/2305.00729.pdf
Summary
contrastive learning (CL) 과 masked image modeling (MIM) 의 representations, downstream tasks에서의 성능을 비교하는 논문이다.
self-supervised ViT가 3가지 특성을 가진다는 것을 보여준다.
(1) CL은 longer-range global patterns를 포착하여 self-attentions를 학습한다. (shape of an object) CL의 이러한 특성은 ViT가 representation spaces에서 이미지를 linearly하게 분리시키는 것을 돕는다. 그러나, 이는 모든 query tokens와 heads의 self-attentions 도 붕괴되는데, 이는 representations의 다양성을 감소시키고, scalability와 dense prediction performance를 악화시킨다.
(2) CL은 representations의 low-frequency signal 을 활용하고, MIM은 high-frequency signal 을 활용한다. low, high frequency 정보는 각각 shapes와 textures를 표현한다. 즉, CL은 shape-oriented, MIM은 texture-oriented 하는 것이다.
CL - 형태,모양에 중점 // MIM - 텍스쳐,질감에 중점
(3) CL은 later layers에서 중요한 역할을 하는 반면, MIM은 early layers에서 중요한 역할을 한다.
==> CL와 MIM은 상호보완적이며, 이 둘을 적절히 조합하면 그들의 장점을 합칠 수 있을 것이다.
How do self-attentions behave?
- CL은 주로 global relationships 포착, MIM은 local relationships 포착
- CL의 representations에는 MIM보다 object shapes같은 global patterns를 더 포함되어있다는 것

How are representations transformed?
- CL은 image-level information을 기반으로 representations를 변형하고, self-attentions는 전체 token을 통해서 object shape에 대한 정보를 얻기 때문에 token들이 비슷해진다. => CL은 이미지는 잘 구분하지만, token을 잘 구분하지 못한다.
- MIM은 token-level 정보를 보존하고 증폭시키기 때문에 각 token의 self-attentions가 서로 다르고, 이는 중복된 정보가 포함되지 않도록 한다.
- CL은 low-frequency signal, MIM은 high-frequency signal 을 활용한다. => CL은 shape-biased, MIM은 texture-biased이다.
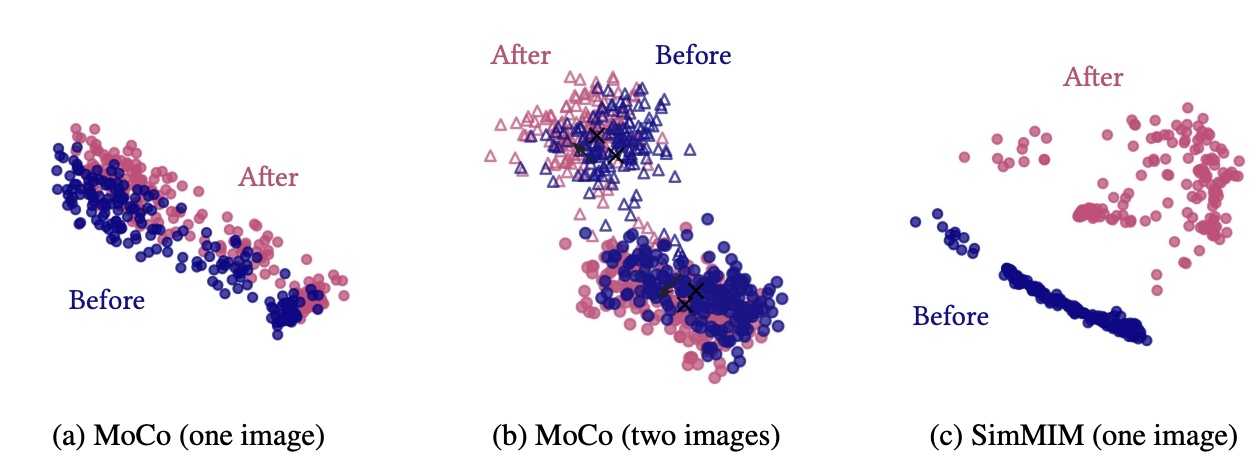
Which components play an importatnt role?
- CL은 later layers에서, MIM은 early layers에서 중요한 역할을 한다.
- early layers가 low-level features를 포착한다. (local patterns, high-frequency signal, texture information)
- later layers가 (global patterns, low-frequency signals, shape information)를 포착한다.
'Computer Vision > 논문' 카테고리의 다른 글
| [simMIM] SimMIM: a Simple Framework for Masked Image Modeling (0) | 2023.05.21 |
|---|---|
| [MAE] Masked Autoencoders Are Scalable Vision Learners (0) | 2023.05.18 |
| [SimSiam] Exploring Simple Siamese Representation Learning (1) | 2023.05.04 |
| [논문] Single-Image Depth Perception in the Wild (0) | 2023.05.03 |
| [논문] Deeper Depth Prediction with Fully Convolutional Residual Networks (0) | 2023.05.03 |
