(23.03.18)
overfitting (과적합) & underfitting (과소적합)
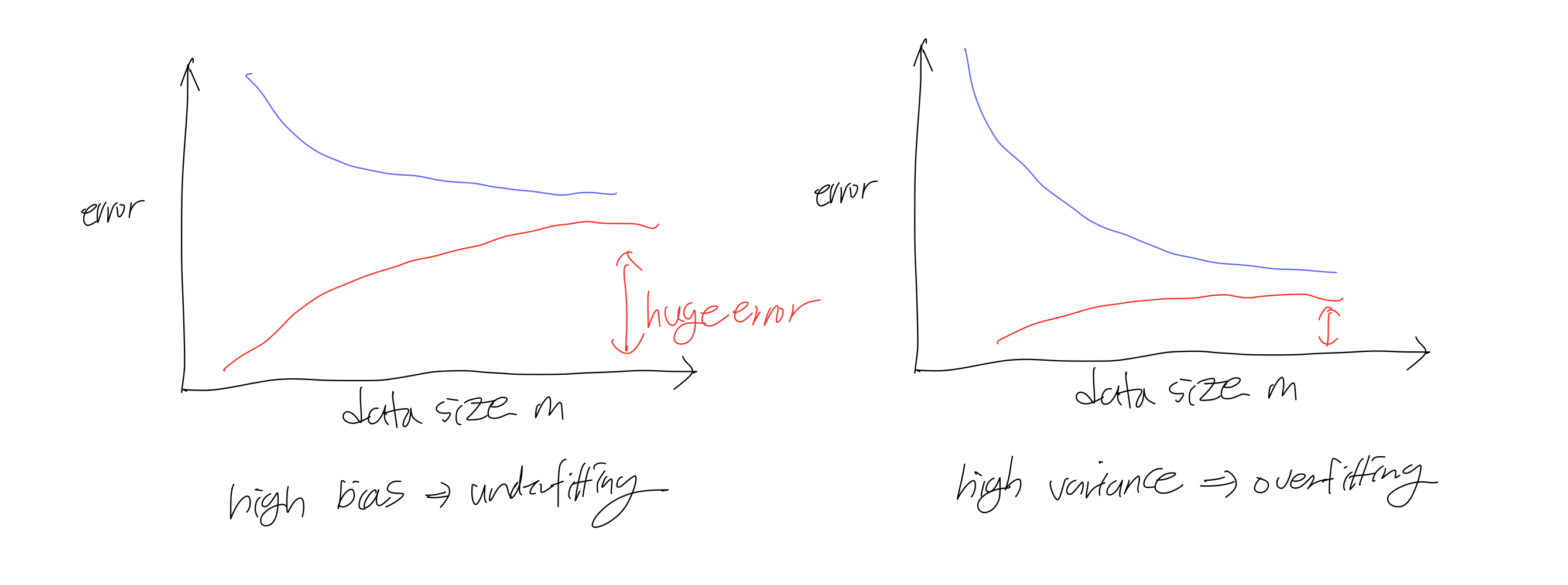
overfitting problem
: 모델이 training data에 지나치게 fitting하여 새로운 data에 대한 예측을 제대로 하지 못하는 것으로 일반화능력이 떨어지는 문제이다.
- 학습하는 과정에서 error를 무조건 낮게 학습시키는 것은 overfitting을 초래할 수 있다.
- overfitting 해결책 #1. feature 수 줄이기
- 어떤 feature를 유지할 것인가? -> model selection algorithm
- overfitting 해결책 #2. regularization: feature들을 모두 유지하는 방법
- parameter(weights)들을 모두 조절해서 고차원 feature들의 영향을 줄여준다.
underfitting probelm
: 모델이 너무 간단해서 training data를 제대로 설명하지 못하는 문제이다.
- underfitting 해결책: feature 수 늘리기
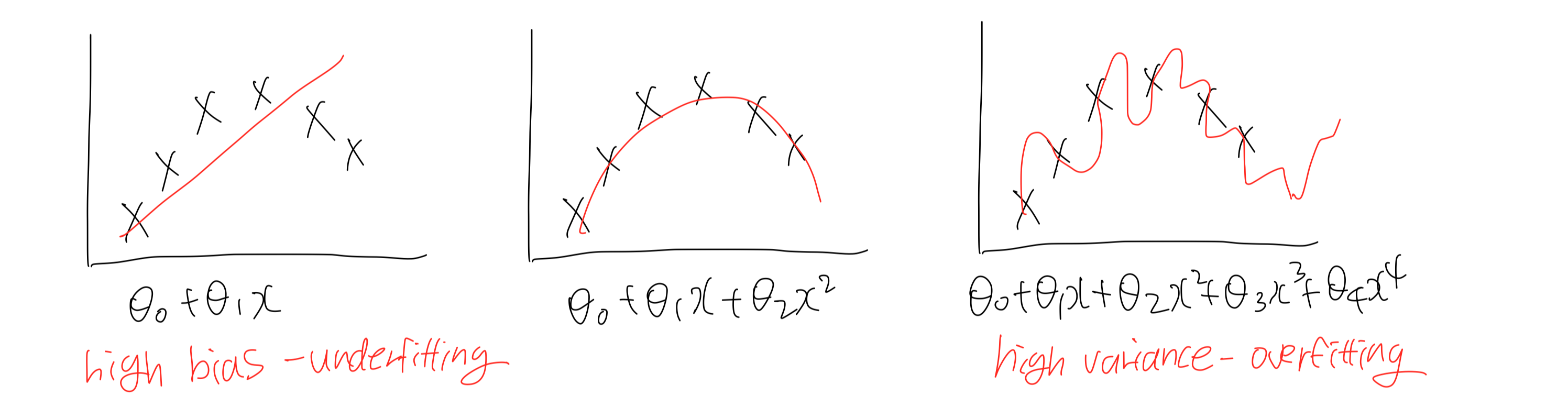
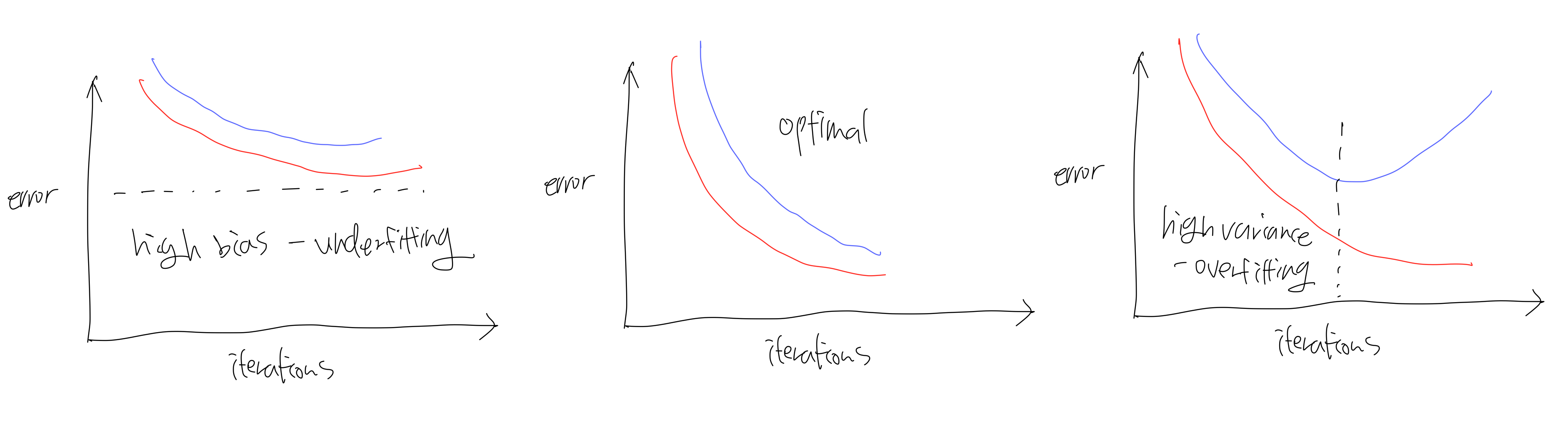
- bias error: 모델이 input에 대한 잘못된 예측값으로부터의 error
- variance error: small input noise에 대한 sensitivity로부터의 error
- training error: training data에 대한 model error
- generalization error: new data에 대한 model error
regularization
- overfitting을 방지하기 위한 기법이다.
- feature 개수는 유지하면서, parameter의 강도를 조절한다. (feature의 영향을 줄여준다.)
regularization - linear regression
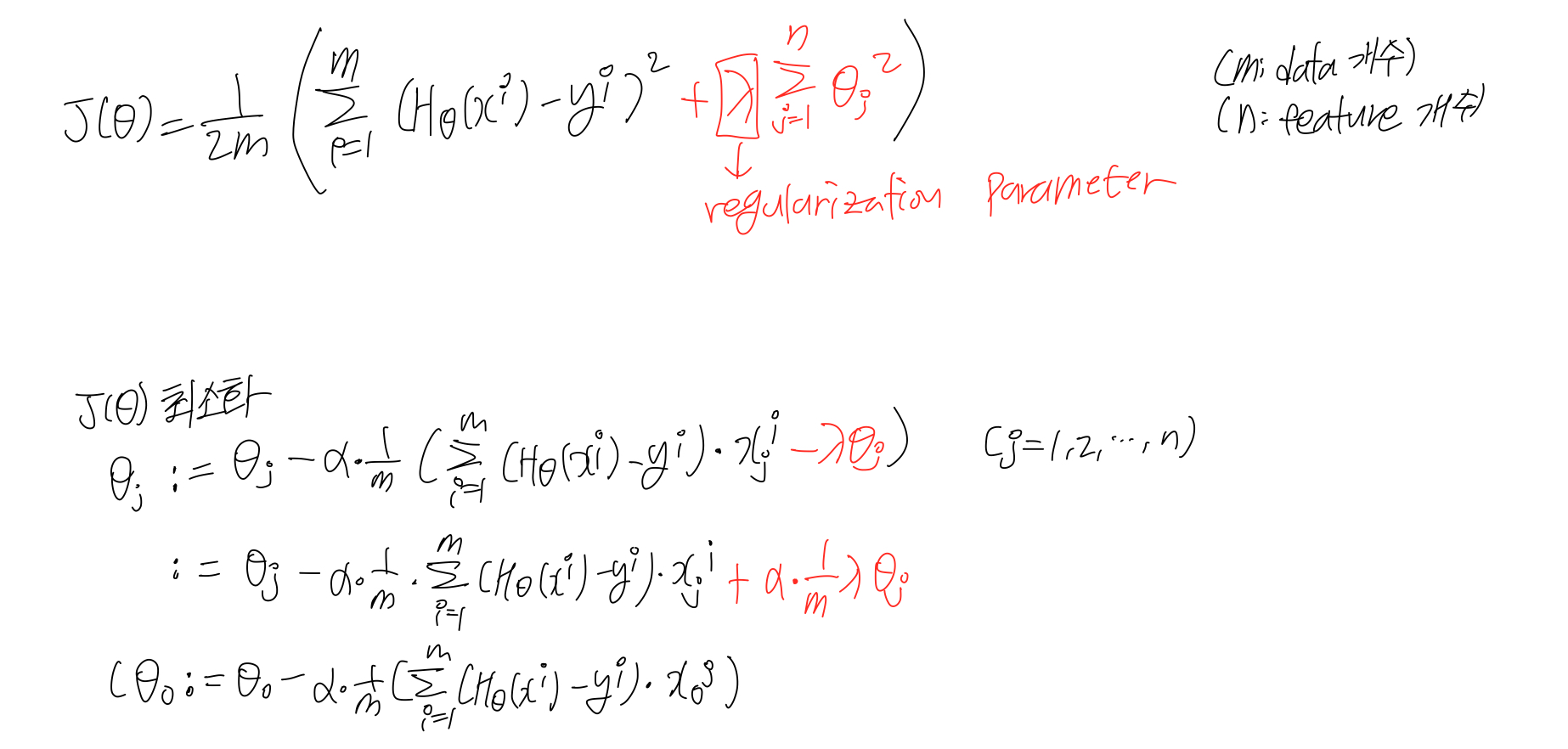
regularization - normal equation
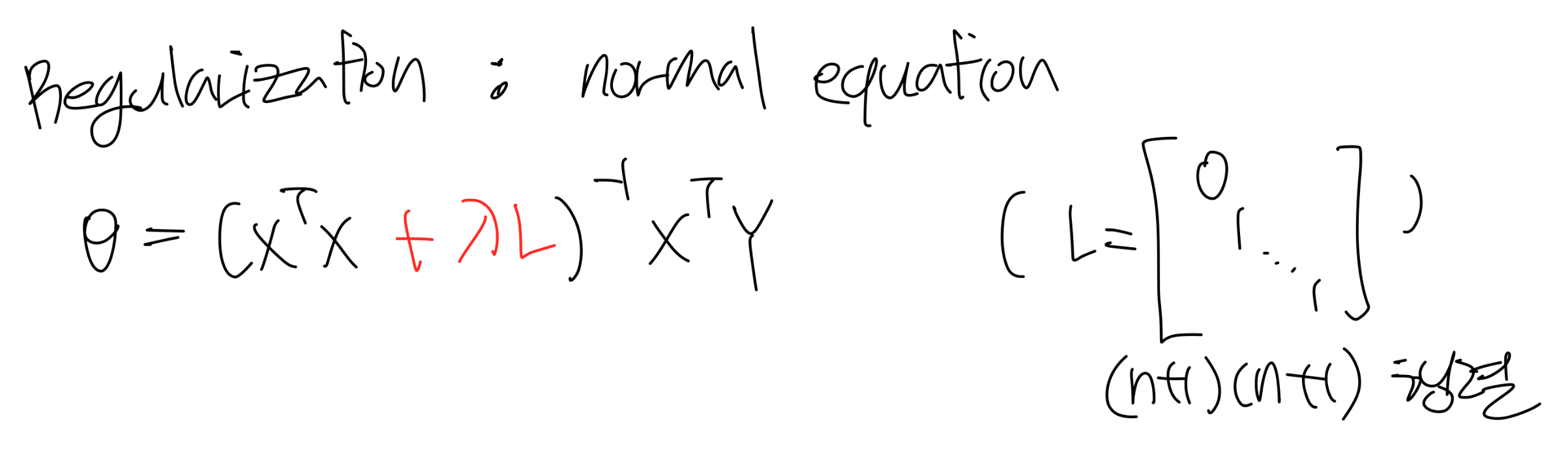
regularization - logistic regression
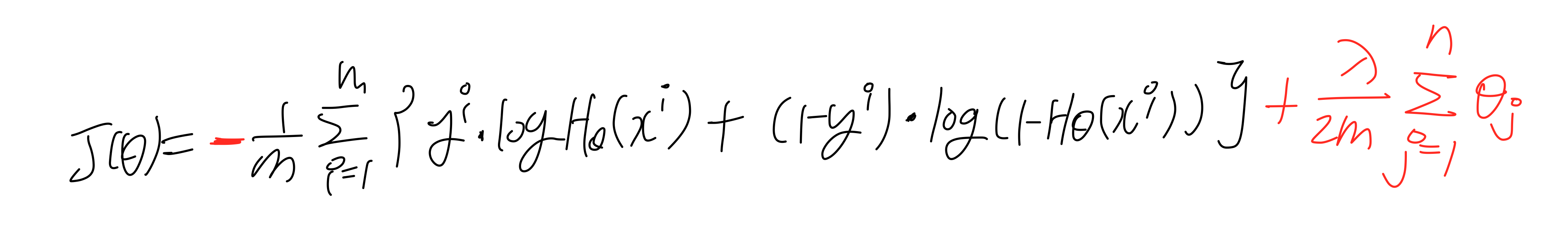
model selection
- validation set: hyperparamter를 튜닝하는데 사용하는 data set

- training set -> 모델 학습
- validation set -> evaluate
------> 가장 적은 error나온 모델 고름 (hyperparameter 설정)
- full-training data set (training + validation) -> 다시 모델 학습
- test set -> trained model 성능 평가
k-fold validation
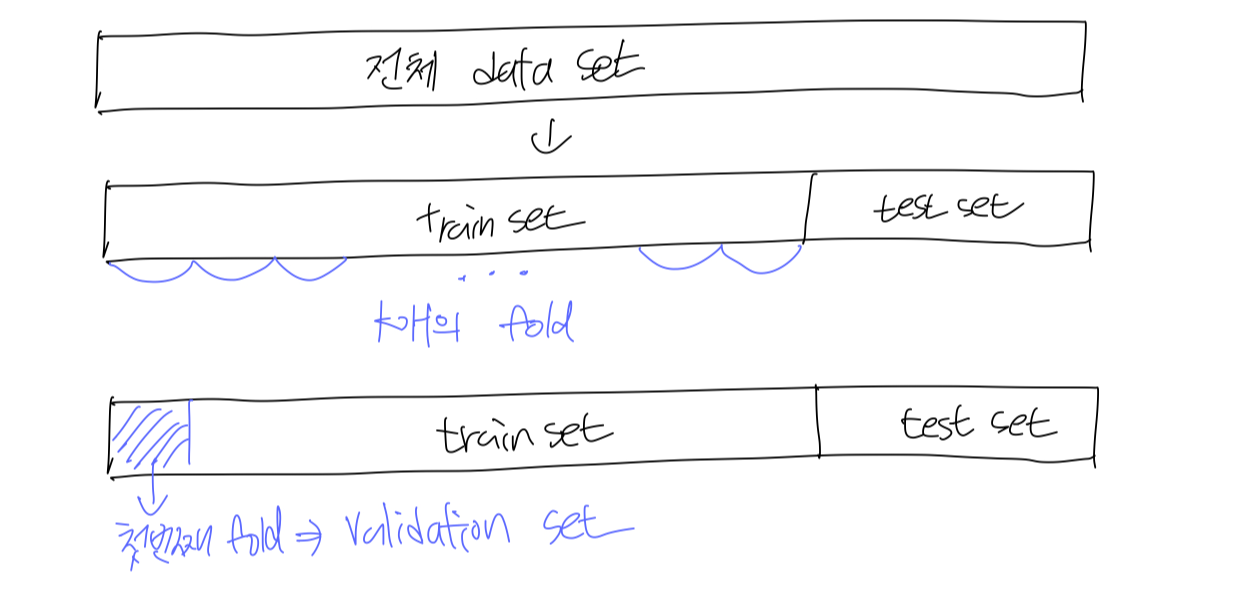
- 전체 data set을 train set과 test set으로 나눈다.
- train set을 k개의 fold로 나눈다.
- 그 중 첫번째 fold를 validation set으로 지정한다.
- training set으로 모델 학습하고, validation set으로 모델 평가한다.
----> 위 과정을 k번 반복한다. (k번째 fold를 validation set으로 사용)
- k개의 test 결과의 평균이 해당 모델의 성능이다.
그 외 다양한 상관관계 그래프들...