(23.03.17)
suervised learning, 기계학습의 대표적인 방법인 linear regression 을 정리해보았다.
linear regression 관련된 코드 구현 ><
https://github.com/gompaang/machine_learning_practice/blob/main/code/linear_regression.ipynb
GitHub - gompaang/machine_learning_practice
Contribute to gompaang/machine_learning_practice development by creating an account on GitHub.
github.com
Linear regression

linear regression은 종속변수 y와 독립변수 x와의 선형 상관관계를 모델링하는 회귀 분석 기법이다.
> hypothesis 가설 함수를 세우고 (parameter) , loss function을 세운다. 기본적인 가설함수로는 parameter가 2개인 일차함수 형태가 있다. loss function은 주로, 예측값과 실제값 차이의 제곱을 계산하는 함수로 둔다. (mean square loss)
> loss function의 기울기를 계산하여 loss function을 최소화하는 지점을 찾고자 gradient descent 기법을 사용한다.
> loss function을 최소화하는 parameter를 찾아 데이터를 가장 잘 표현하는 hypothesis 가설 함수를 완성하는 것이 최종 목표이다. 그리하여, 새로운 데이터가 들어와도 가설함수를 거쳐 잘 예측할 수 있도록 한다.

gradient descent 알고리즘
- loss function을 최소화하는 parameter를 어떻게 찾을까? -> gradient descent 알고리즘 사용하자!
- hypothesis 가설 함수의 기울기를 계산하고, 그 기울기의 반대방향으로 이동시켜 극값으로 가도록 하는 방법이다.

- gradient descent의 learning rate가 고정되어있더라도, gradient descent는 수렴한다. 왜냐면, local minimum에 가까워질수록 미분계수 값은 작아지고, 하강기울기의 움직이는 정도는 더 작아지기 때문이다. 그렇기 때문에 gradient descent를 수렴하게 하기 위해서 반드시 learning rate를 감소시킬 필요는 없다.
- learning rate는 우리가 직접 설정해주어야하는 hyperparameter로 너무 작으면 gradient descent 수렴속도가 느려지고, 너무 크면 gradient descent는 minimum 으로 수렴하지 못하고 발산하게 된다.
"batch" gradient descent
- 여기서의 batch는 보통 쓰이는 batch와는 의미가 살짝 다르다. 여기서의 batch는 모든 training dataset을 말한다.
- 모든 training dataset을 gradient descent에 사용하는 것이다. -> 전체 data에 대한 업데이트가 한번에 이루어진다. 즉, 업데이트 횟수가 적고, 전체적인 계산 횟수가 적다. optimal 로의 수렴이 안정적이며, 병렬처리에 유리하다.
- 그러나, 한 step에 모든 traininng dataset을 사용하므로 학습하는데에 오래걸린다. 그리고, 전체 dataset의 error를 모델이 업데이트하기 전에 축적해야하므로 memory가 많아야한다. 또한, local optimal 상태에서 빠져나오기 다소 힘들다.
"stochastic" gradient descent
- traning dataset에서 랜덤하게 dataset을 골라 그 dataset만 학습시킨다.
- dataset이 적어서 실행속도와 수렴속도가 빠르고, local optimal에 빠질 위험이 적다.
- 그러나, 랜덤하게 고른 dataset의 편향으로 성능이 들쭉날쭉할 수 있다. 또한, global optimal을 아예 찾지 못할 수도 있다.
"mini-batch" gradient descent
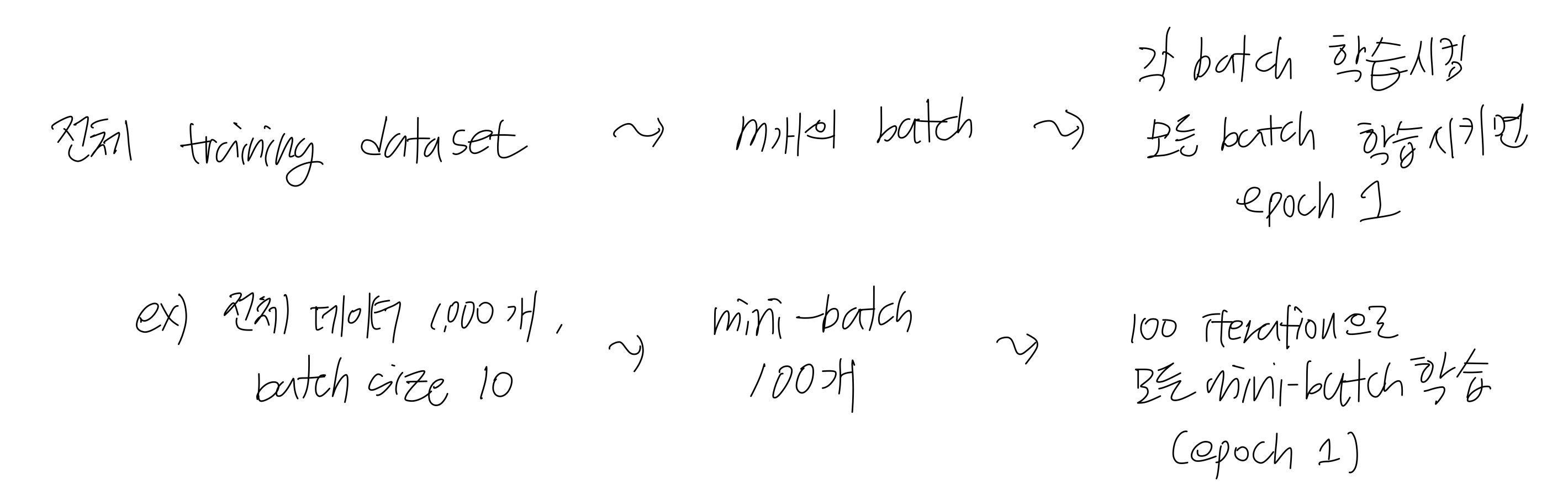
- 전체 training dataset에서 일부 m개의 mini-batch를 만들고, 이를 각각 학습한다. 즉, 각각 gradient descent를 수행한다. m개의 mini-batch의 평균 기울기를 통해 모델을 업데이트하는 방식이다.
- BGD보다 local optimal에 빠질 위험이 적으며, 메모리 사용이 적다.
- batch size는 우리가 설정해주어야하는 hyper parameter이다. batch size는 보통 2의 제곱 형태이다.
normal equation

- normal equation은 X와 Y를 행렬로 보고 수식적으로 계산하는 방법이다. normal equation을 통해서 loss function을 최소화하는 parameter를 찾을 수 있다.
- normal equation은 gradient descent와는 다르게 learning rate라는 hyper parameter를 정하지 않아도 되며, iteration 과정이 필요없다. 그러나 역행렬 계산 과정이 O(n^3)이며, features 개수가 많으면 느려진다.
'Computer Science > Machine Learning' 카테고리의 다른 글
| [machine learning] 3. Logistic Regression (binary classification) (0) | 2023.03.18 |
|---|---|
| [machine learning] 2. Multivariate Linear Regression, Polynomial Linear Regression (locally-weighted linear regression) (0) | 2023.03.18 |
| [machine learning] 0. Introduction (0) | 2023.03.17 |
| [ML] 비지도학습 - 군집화(clustering) (0) | 2022.04.09 |
| [ML] 지도학습 - 분류(classification), 앙상블(Ensemble) (0) | 2022.04.07 |
