(23.01.22)
ViT 논문 정리 1탄
computer vision에 transformer 열풍을 불러일으킨 논문이다. transformer관련 지식이 없어서 관련 이전 논문들을 읽고 읽었다.
- 논문 제목: An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale (ICLR 2021)
- https://arxiv.org/pdf/2010.11929.pdf
Abstract
- transformer 아키텍쳐는 nlp task에서 기본이 된 반면, computer vision 분야에서는 적용에 한계가 있었다.
- 그러나, CNN에 의존할 필요가 없으며, pure transformer를 image patches의 sequence로 적용하면 image classification task에서 매우 좋은 성능이 나온다.
- 많은 양의 data로 pre-training하고, ImageNet, CIFAR-100같은 multiple mid-sized나 small imgae recognition benchmarks에 transfer하면, Vision Transformer (ViT)는 sota convolution networks와 비교했을 때, 좋은 결과가 나온다.
- 또한, ViT는 학습시키는데 더 적은 computational resources를 요구한다.
Introduction
NLP에서의 transformer의 성공을 vision으로 가져오기 위해서는 image에 적용하기 위해서는 약간의 변형이 필요하다.
-> image를 patches로 분리하고, 이 patches들의 linear embedding sequence를 transformer의 input으로 넣는다.
-> image patches는 NLP에서의 tokens로 생각하면 된다.
transformer는 inductive biases가 부족하다 (CNN에 비해서)
-> inductive bias는 translation equivariance, locality 라고 생각하면 된다.
그래서 많은 양의 데이터로 학습시켜주었을 때 transformer의 성능이 좋게 나온다.
Method

(요약)
image를 2D patch로 바꾸고, D차원으로 linear projection 시켜준다. classification token을 추가하여 patch + position embedding을 해준다. 그 결과를 transformer encoder에 넣어준다. (norm+MSA)+residual + (norm+MLP)+residual 의 구조로 되어있는 transformer encoder를 통과하고, MLP head를 지난다.
ViT를 large dataset에 pre-train시키고, downstream task에 fine-tune하는데, fine-tune할 때에는 prediction head(MLP head)를 제거하고, zero-initailized DxK feedforward layer를 붙인다. (K는 downstream task의 클래스 갯수)
(상세한 설명 - embedding 부분)
image를 sequence of flattened 2D patches로 바꾼다.
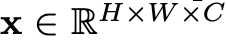

(HxW) = original image의 resolution
C = channel의 갯수
(PxP) = 각 image patch의 resolution
N = patches들의 갯수 (HxW/P^2)
flattend 2D patches는 D차원으로 linear projection시켜준다.
learnable 'classification token'을 sequence 맨앞에 넣어준다. 아래 식(1)의 x_class가 이에 해당한다.
그 뒤에는 patch embedding을 해주는데, 이때 position embedding도 한다. (learnable 1D position embedding) positional information을 추가해주기 위해서이다.

(상세한 설명 - transformer encdoer 부분)
이제 이것을 transformer encoder에 input으로 넣어준다.
transformer encoder는 multi-headed self attention, MLP block으로 구성된 여러개의 layer로 구성된다.
LN(layer norm)은 모든 block이전에 적용되고, 모든 block에서 residual connection이 사용된다.

Experiments