(23.01.18)
SSL(self-supervised learning) 논문 리뷰 4탄
이번에 정리할 논문은 DINO라 불리는 논문이다.
- 논문 제목: Emerging Properties in Self-Supervised Vision Transformers (2021)
- https://arxiv.org/pdf/2104.14294v2.pdf
Abstract
self-supervised method를 제안하는데 이것이 바로 self-distillation with no labels (dino)이다.
ViT와 DINO를 함께 사용하여 높은 성능을 이끌어냈다.
저자가 관찰한 내용
- self-supervised ViT features가 sementic segmentation에 대해 explicit information을 포함한다. (supervised ViT, conv-net 들 보다)
- self-supervised ViT features들은 또한 excellent k-nn classifiers이다.
Introduction
ViT 단점: computationally more demanding, require more training data, their features do not exhibit unique properties
저자는 transformer가 NLP에서 성공을 거둔 것은 self-supervised pretraining 이라고 말한다. image-level supervision 은 종종 rich visual information을 줄인다. 이에 vision transformer에도 self-supervised learning을 적용할 방법을 고안하였다.
(abstract 와 겹치는 내용)
self-supervised ViT features는 scene layout, object boundaries 등을 포함하고, k-nn classifier가 된다.
Method


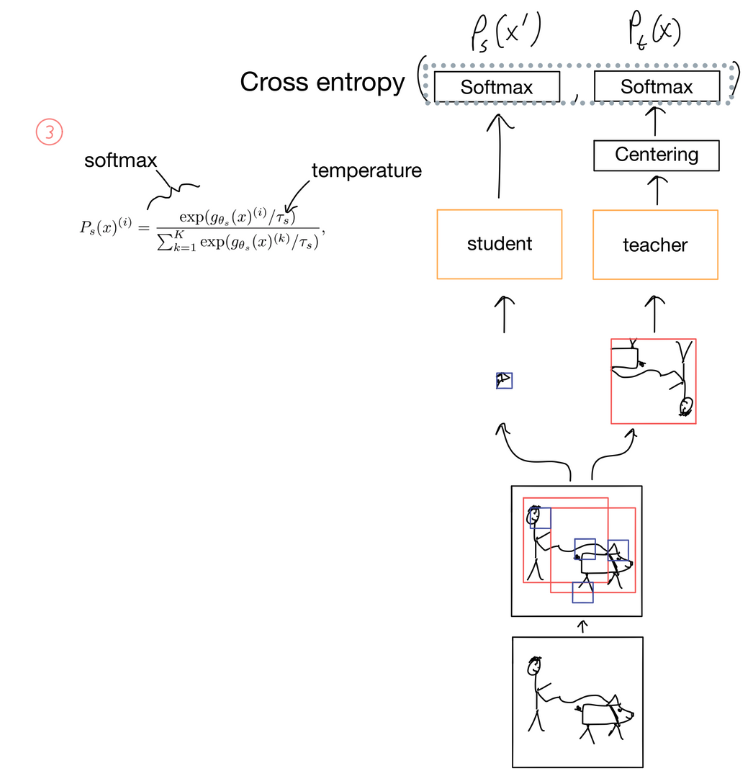
간단하게 말하면, knowledge distillation 은 teacher network 의 결과를 바탕으로 student network를 학습하는 방법이다.
DINO는 student network와 teacher network를 가지고 있는데, 두개의 network는 동일한 아키텍쳐이지만 다른 parameter를 갖는다. teacher network는 stop-gradient가 적용되며, ema(exponential moving average)를 통해 teacher parameter를 update한다.
image의 feature에 대해 softmax함수를 통과시키면 K 차원의 확률 분포를 생성할 수 있다. 해당 확률 분포는 아래와 같다.

두개의 distribution에 H() 연산을 적용하고 이를 최소화하는 방향으로 student network의 학습을 진행한다.


논문에서는 multi-crop 전략을 사용하였는데,
image가 주어지면, 그 image에 대한 224x224 size의 global view 두개를 포함하여 96x96 size의 local view를 포함한 집합 V를 만든다. 아래 식의 V가 집합 V이며, x1^g, x2^g는 global view이다.

global view는 teacher network으로 들어가고, local view는 strudent network로 들어가게 되며, 이에 대한 cross entropy loss를 적용하여 student network를 학습시키는 것이다. 이를 여기서는 local to global이라고 말한다. multi-crop을 다양하게 적용하였을 때, 어떤 방식에서 가장 성능이 좋은지 알 수 있다.

teacher network와 student network는 아키텍쳐가 동일하지만, parameter는 서로 다르다. student network는 back propagation을 통해 파라미터를 업데이트하는 반면에, teacher network는 아래 식에서와 같이 ema를 통해 파라미터가 업데이트 된다.

collapse problem을 해결하기 위한 방안을 몇가지 제시한다. centering과 sharpening인데, 깔끔하게 정리되어 있는 블로그를 가져왔다. (출처: https://github.com/dhkim0225/1day_1paper/issues/56)
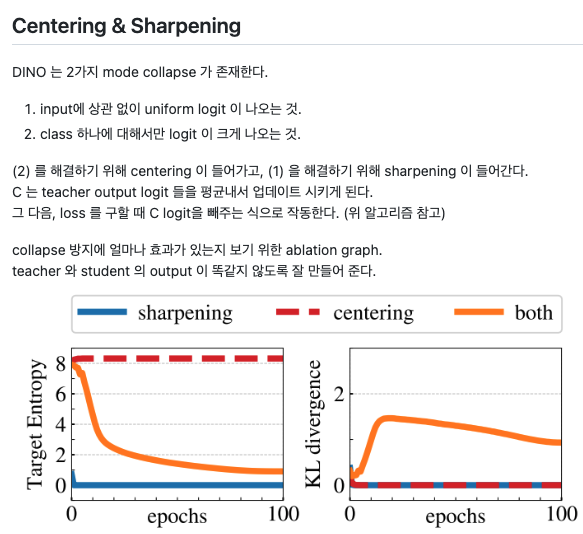
이 method들을 이해하기 쉽게 정리해놓은 그림이 있다 (출처: https://storrs.io/dino/)



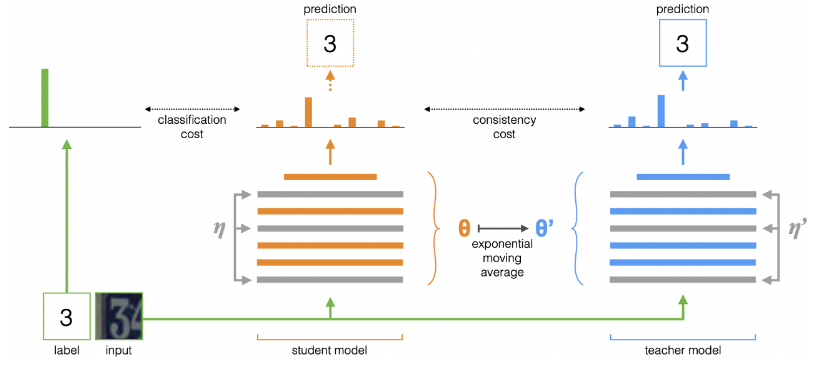
관련 내용으로 mean teacher architecture가 있다. knowledge distilliation 의 한 방법인데, 아래 그림으로 설명할 수 있다.
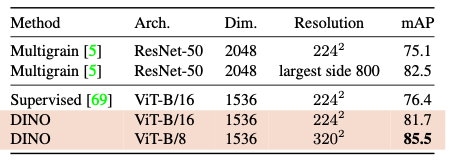
Experiments
중요해보이는 몇가지 실험결과만 가져왔다. DINO의 성능이 가장 좋다는 것을 알 수 있는 결과들이다.

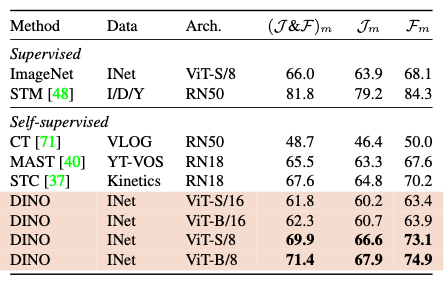
Main contributions
내가 생각하는 DINO에서의 핵심
- student network, teacher network를 사용하여 knowledge distilliation 방식을 ViT와 함께 적용했다는 것
- ema로 teacher network를 학습시킨 것 (다른 knowledge distilliation 방식은 teacher network의 parameter가 fix 되어있음)
- multi-crop
