(23.01.17)
SSL(self-supervised learning) 논문 리뷰 3탄
이번에 정리할 논문은 BYOL라 불리는 논문이다.
- 논문 제목: Bootstrap Your Own Latent A New Approach to Self-Supervised Learning (NeurIPS 2020)
- https://arxiv.org/pdf/2006.07733.pdf
Abstract
- 저자는 self-supervised image representation learning의 새로운 접근 방식인 BYOL 을 제안한다.
- BYOL은 2개의 neural networks로 구성되며 이는 각각 online, target network로 불린다.
- augmented view of an image에 대해서 online network를 학습시키고, 같은 image의 다른 augmented view의 target network representation을 예측한다.
- online network의 slow-moving average를 통해 target network를 update시킨다.
- 또한, BYOL은 기존의 sota method들과는 다르게 negative pairs를 사용하지 않았다.
Introduction
- 기존의 contrastive learning의 경우, negative pairs의 의존도가 높아 큰 batch size에서 학습시켜야 했고, 성능이 image augmentations에 많은 영향을 받았다.
BYOL 등장!!

-> BYOL이 기존의 ssl 모델에 비해 성능이 높고, supervised model의 성능에 훨씬 가깝다는 실험 결과
- BYOL은 negative pair를 사용하지 않았다고 했는데, 바로 이것이 image augmentations에 대한 robustness를 향상시켰다고 본다.
- augmented view of an image로 시작하여, BYOL은 같은 image에 대한 다른 augmented view의 target network의 representation을 예측하도록 online network를 학습시킨다.
- BYOL은 collapsed problem에 대한 해결책을 제시한다.
1) online network에 predictor 추가
2) online parameters에 slow-moving average 사용
Method

앞에서 말했듯 BYOL은 2개의 neural network로 구성되어 있다. -> online & target
각각의 network는 encoder, prejector, predictor로 구성되어있고, weight는 서로 다르다.
target network는 online network가 배울 regression target을 만들고, target network weight은 online network weight들의 exponential moving average값을 사용한다.
2개의 network에 서로 다른 augmentation을 적용해서 feauture vector 추출하고, l2 normalize 시켜서 나온 mse를 최소화하는 방향으로 online network를 학습시킨다.
[내가 이해한 것]
target network에 augmented image넣어서 나온 prediction이 있다.
같은 이미지의 다른 augmented image를 online network에 넣어서 나온 prediction을 앞선 target network의 prediction과 비교하고 논문에서 나온 loss function을 통해 loss를 최소화하는 방향으로 online network를 학습한다.
target network는 online network weight들의 exponential moving average를 사용하여 업데이트한다.
- parameter update

- loss function

- optimizer
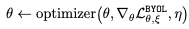
Experiments


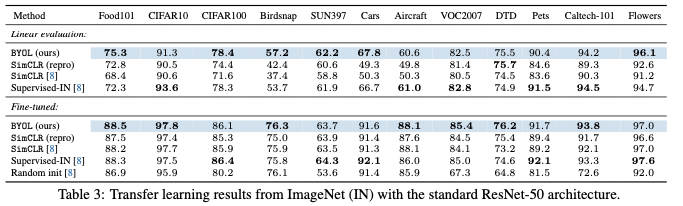
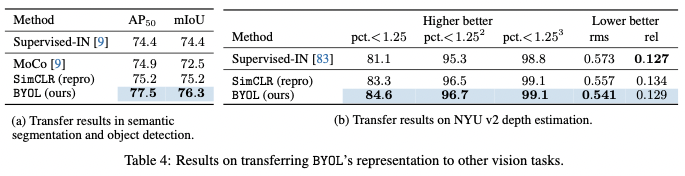
main contributions
- negative pairs를 사용하지 않은 self-supervised representation learning method의 새로운 method (BYOL)를 제안
- BYOL은 batch size와 data augmetation의 변화에 robust 하다. (기존의 contrastive learning의 문제점 개선)
