(23.02.08)
SSL(self-supervised learning) 논문 리뷰 7탄
self supervised learning에 ViT backbone을 사용한 논문이다..!
기존 MoCo의 일부분이 변경되었다.
- 논문 제목: An Empirical Study of Training Self-Supervised Vision Transformers (ICCV 2021)
- https://arxiv.org/pdf/2104.02057.pdf
Abstract & Introduction
본 논문에서 다루고자하는 것은 self-supervised learning for Vision Tranformers (ViT) 이다.
NLP와 vision 의 차이점은 2가지이다.
- NLP는 maksed auto-encoders를 learner로, vision은 siamese network를 learner로
- NLP는 self-attentional Transformer를 backbone으로, vision은 convolutional deep residual network(ResNet)를 backbone으로
Method

MoCo v3의 구조는 기존의 MoCo v1, v2와 같다.
각 image에 대해 random data augmentation시켜주고 crop하여 x1, x2를 만든다. query encoder(f_q)와 key encoder(f_k)를 통과한다. 그리고 통과한 q, k에 대해 loss function을 최소화하도록 query encoder를 업데이트시켜준다.
loss function은 아래와 같다. InfoNCE의 형태이다.
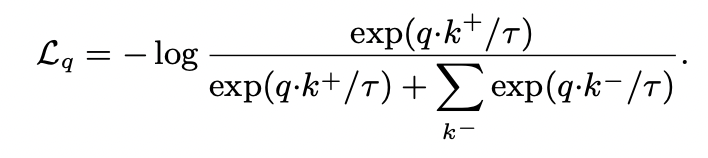
k+: q의 positive sample 에 대한 f_k의 output
k-: q의 negative samples 에 대한 f_k의 output
t: temperature hyper-parameter (l2-normalized q, k)
MoCo v3의 핵심 !!
- key 들이 same batch에 있다.
- memory queue를 버리고 큰 batch size를 통해 실험했다.
- symmetrized loss 를 사용했다. ctr(q1, k2) + ctr(q2, k1)
- encoder(f_q) = backbone(ResNet, ViT) + projection head + prediction head
- encoder(f_k) = backbone(ResNet, ViT) + projection head
- f_k는 prediction head를 제외한 f_q의 moving average에 의해 업데이트 된다.

Stability of self supervised ViT training
MoCo v3에 ViT를 넣어 학습시켰더니 trainig curve에서 매우 불안정한 모습이 나타났다. 저자는 다양하게 실험을 해보면서 어떻게 하면 안정적으로 할 수 있을지를 고민해봤다.
- batch size: 4096이 가장 적당
- learning rate: linear scaling rule (lr * batch_size / 256)
- optimizer: LAMB
---> fixed random patch projection : patch를 embedding vector로 바꿔주는 layer를 고정시킨다. 즉, 학습시키지 않는다.
Experiment
본 논문에는 정말 많은 실험들이 있는데, 대표할 수 있는 실험결과만을 가져왔다. 나머지는 세부적인 부분이라 생각.. 필요하다면 다시 논문을 보며 확인하면 될 것 같다.

Main Contribution
- ViT + self supervised learning 을 시도했다는 점
