(23.02.08)
SSL(self-supervised learning) 논문 리뷰 6탄
논문이 3페이지여서 굉장히 빨리 읽을 수 있었다 ^ㅡ^
SimCLR + MoCo ..!! 라고 생각하면 될 것 같다..!
- 논문 제목: Improved Baselines with Momentum Contrastive Learning (2020)
- https://arxiv.org/pdf/2003.04297.pdf
Abstract & Introduction
Contrastive unsupervised learning -> SimCLR, MoCo
본 논문에서는 SimCLR의 2가지를 MoCo에 적용하여 MoCo v2를 제안한다.
MLP projection head + data augmentation
(이는 SimCLR과 다르게 large training batch size가 필요없다!!)
그리고 cosine learning rate schedule을 추가한다.
Contrastive learning이란?
positive/negative pairs로 이루어진 데이터로부터 positive/negative representation을 학습하는 framework이다.
contrastive loss function: InfoNCE

q: query representation
k+: representation of the positive key sample
k-: representation of the negative key samples
t: temperature hyper-parameter
Method
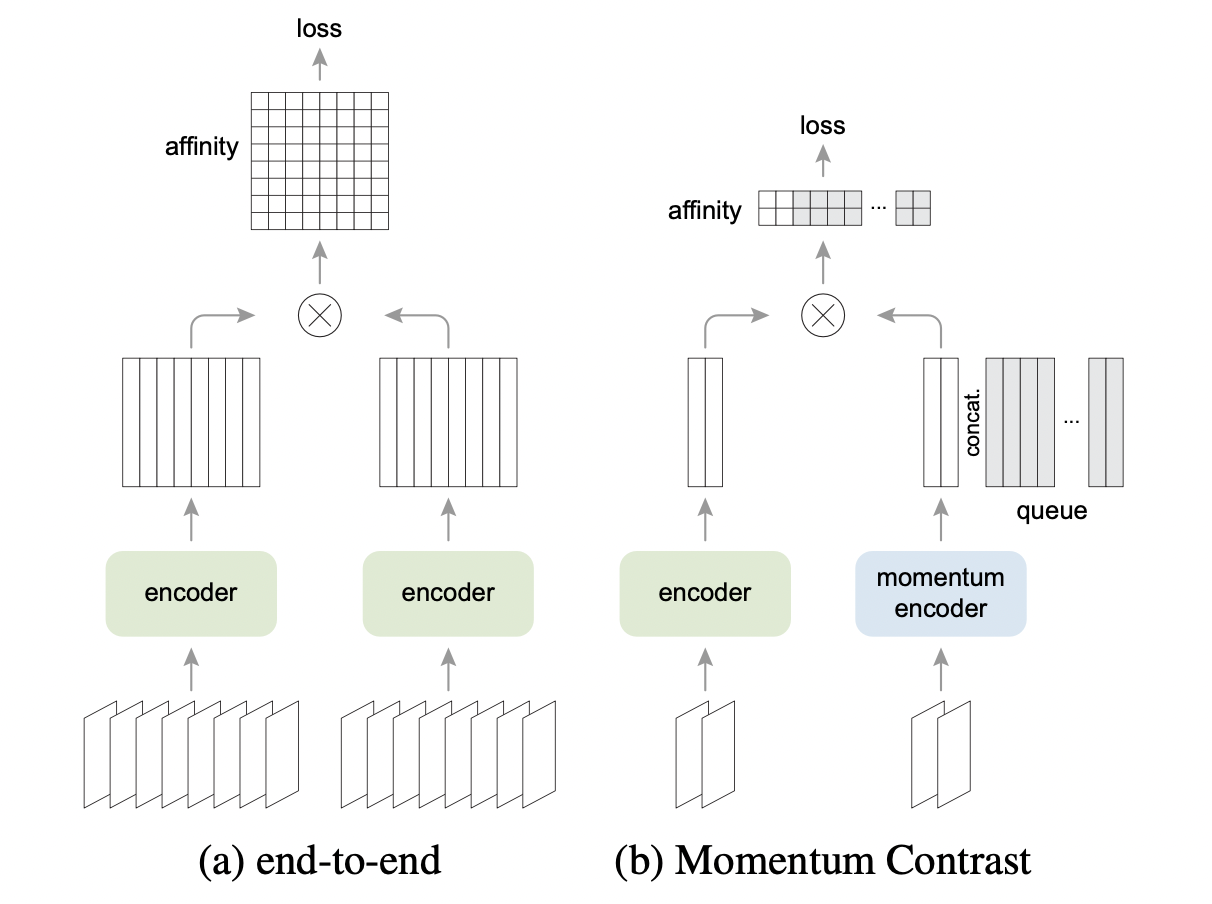
SimCLR은 그림 (a)다.
negative key들은 같은 batch로부터 나오고, end-to-end back propagation으로 업데이트된다.
MoCo는 그림 (b)다.
negative key들은 queue에 있고, queue가 batch 역할을 한다 (?)
MoCo v2
1. MLP projection head
MoCo는 ResNet의 gloabl average pooling layer와 연결된 linear layer가 기본 encoder였는데, SimCLR의 구조를 가져왔다.
SimCLR은 ResNet의 global average pooling layer까지만 가져오고 그 뒤에는 MLP projection head를 붙인 것을 기본 encoder로 사용했다.
2. data augmentation
SimCLR에서 data augmentation을 여러개 조합하여 사용한 것처럼 여러가지 실험을 통하여 original augmentation에다가 blur augmentation을 추가했다.
3. cosine learning rate scedule
SimCLR에서 cosine learning rate scedule을 사용하는데, MoCo v2는 이를 가져와서 사용했다.
Experiment
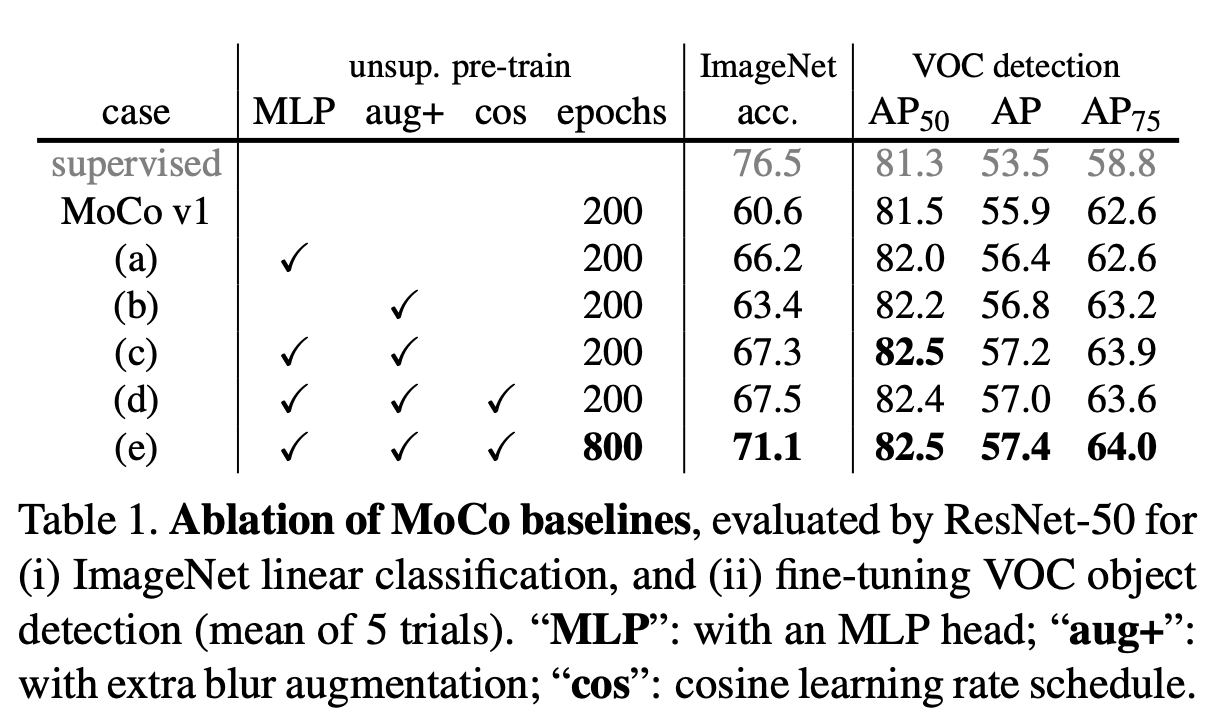
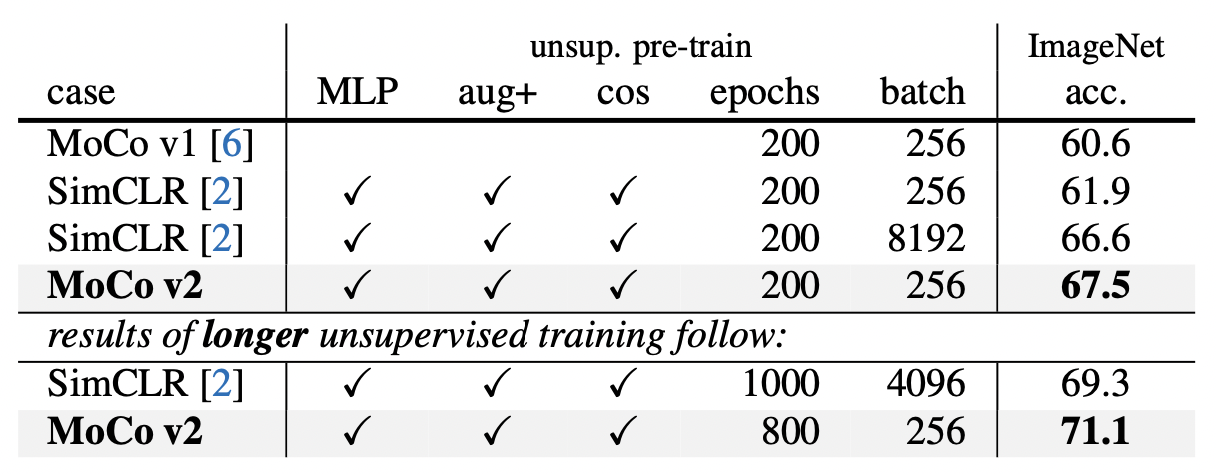

end-to-end의 computational cost가 더 높은 이유는 end-to-end는 query, key encoder를 모두 update시키는 반면, MoCo는 query encoder만 업데이트 시키기 때문이다.
Main Contribution
- MoCo에다가 SimCLR의 MLP projection head를 가져온 점
- augmentation, cosine learning rate scedule을 덧붙인 점
