(2022.03.26)
기계학습 수업들으면서 정리하기 6탄
Lecture3_ML 내용정리-2
Pandas
numpy는 2차원 행렬 형태의 데이터를 지원함--> 데이터 속성을 표시하는 행과 열의 label을 가지고 있지 않음
--> python pandas 패키지로 문제 해결
- 2가지 데이터 구조 제공: 시리즈, 데이터프레임
- 시리즈: 동일 유형의 데이터를 저장하는 1차원 배열
- 데이터프레임: 시리즈 데이터가 여러 개 모여 2차원적 구조를 갖는 것
- 각 행과 열의 이름 부여 --> 행: index, 열: columns

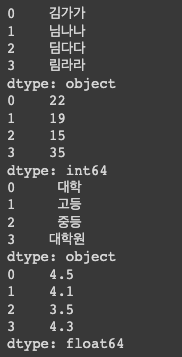
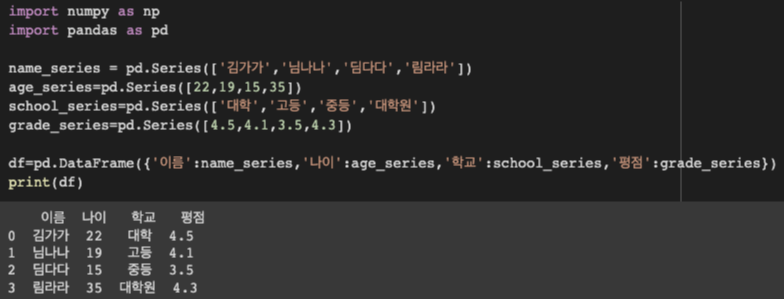
--> 시리즈를 모아 하나의 데이터프레임으로 만들 수 있음
--> pandas의 DataFrame 클래스 이용
--> python의 딕셔너리 구조: key-열의 이름 , value-데이터
pandas 로 데이터 읽고 확인하기
- pandas 모듈: csv 파일을 읽어 데이터프레임으로 바꾸는 작업 가능 --> read_csv 함수이용
- csv 파일은 1) 동일한 자료형 가진 시리즈, 2) 각 행이 같은 구조 이어야 함.

--> 가장 왼쪽 열을 보면, 자동으로 인덱스가 생성되어있는 것을 볼 수 있음

--> index_col 매개변수에 0 넣어주면, 첫번째 열이 인덱스로 사용됨

--> 데이터 프레임에서 특정한 열만 선택할 수 있음
--> index_col=0을 인자로 넣은 경우: 첫번째 열이 index로 사용됨
--> 인자 없는 경우: 첫번째 열에 자동으로 숫자 index가 생성됨

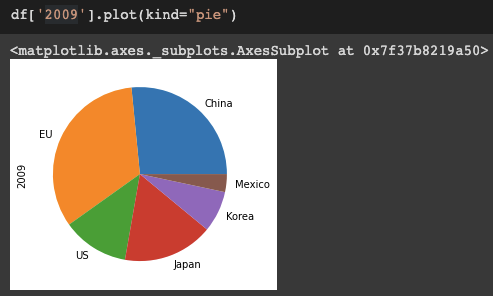
--> plot( ) 메소드 사용, kind='bar' , kind='pie' 를 통해 그림으로 표현 가능함 (pie 는 색상 지정 못함)

--> head( ) , tail( ) 을 이용하여 슬라이싱 가능 -> 행에 대한 슬라이싱

--> 슬라이싱 표기법으로 슬라이싱 가능함
--> 행의 index를 사용하여 행 선택가능 loc[index]
--> 열과 행을 선택하여 추출가능함
--> loc[index] 로 행 선택하고, 열의 label 선택하여 특정 효소 하나 추출가능함

--> 기존 열의 정보를 바탕으로 새로운 열 생성 가능함 (열: axis=1)

--> describe( ) 메소드를 통해서 데이터 분석이 가능함
count: 개수, mean: 평균, std: 표준편차, min: 최솟값, max: 최댓값
결손값
- 데이터과학과 머신러닝에서 사용하는 데이터는 상당한 수의 결손값을 가짐
- 데이터를 처리하기 전에 거쳐야하는 절차가 바로 데이터 정제임

--> 데이터 수에 차이가 있는 것을 볼 수 있음

--> isna( ) 를 통해 결손값이 있다면 NaN으로 반환함 (Not a Number)
결손값 다루는 방법
1) dropna( ) : 결손값을 가진 행/열을 삭제할 수 있음
2) fillna( ) : 결손값을 다른 값으로 교체할 수 있음
--> 결손값을 0으로 채우면, 왜곡 가능성이 있기 때문에 평균값으로 채움
But, ML과 DL 에서는 사실 data를 잘 버리지 않음
--> 잘못된 데이터도 의미가 있을 수 있고, 어디에든 사용할 수 있기 때문

그룹핑과 필터링
- 데이터 분석 시, 특정한 값에 기반하여 데이터를 그룹으로 묶는 일이 많음
- groupby ( ) : 그룹핑
- 논리 인덱싱 : 필터링

(* read_csv 인자로 index_col=0 넣어주지 않도록 주의)
데이터 구조 변경 + 병합
1) pivot ( ) : 테이블 구조 변경



--> index로 item열, columns로 type열 (데이터 구조 변경)
2) concat ( ) : 데이터 테이블 결합 --> inner 는 교집합, outer는 합집합
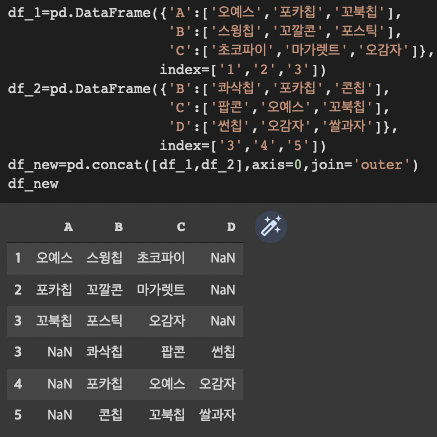
pandas.concat(df_list, axis=0, join='outer')
-> axis=0 이면 행을 늘려 붙이고, axis=1 이면 열을 늘려 붙임
-> join='outer' 면 합집합, join='inner'이면, 교집합

--> index 3은 두 dataframe에 각각 존재했는데, 별도의 행으로 합쳐지는 것을 확인할 수 있음
3) merge ( ) : join과 같은 방식으로 데이터 병합
merge(df, how='inner', on='B')
- how 에는 left, right, inner, outer 들어가는데 보통 outer
- on 에는 df의 columns 가 들어감 (두 dataframe 에 모두 존재하는 label)

--> C lable도 두개의 data frame에 있었기 때문에 C_x, C_y 두개가 나타나고, 각각 왼쪽/오른쪽 테이블에서 가져온 것임


--> inner 로 하면, 교집합으로 3 행만 남음
--> inner는 교집합 --> 행
'Computer Science > Machine Learning' 카테고리의 다른 글
| [ML] 다변량 선형 회귀 분석 - 정규화 & 표준화 (0) | 2022.04.02 |
|---|---|
| [ML] Linear Regression (선형회귀) & Normal Equation (정규방정식) (0) | 2022.04.02 |
| [ML] Numpy 활용 (0) | 2022.03.26 |
| [ML] 과적합 & 과소적합 (0) | 2022.03.26 |
| [ML] Gradient Descent : 경사하강법 (0) | 2022.03.26 |
