(2022.03.26)
기계학습 수업들으면서 정리하기 5탄
Lecture3_ML 내용정리-1
( *실습은 구글 코랩환경에서 python으로 이루어짐 )
( 데이터처리패키지 - numpy, pandas )
( 머신러닝 도구 - scikit learn, tensorflow )
Numpy
: 머신러닝을 위한 데이터 처리의 핵심 도구
데이터 처리를 위해서는 리스트와 리스트 간의 다양한 연산이 필요
--> but, python 기본 리스트는 기능 부족, 연산 속도 느림
--> numpy 배열 선호
numpy의 배열은 1차원 - 벡터, 2차원 - 행렬 로 간주하여 연산
numpy의 핵심 객체는 다차원 배열
- 배열의 각 요소: 인덱스(index) -정수
- 차원: 축(axis)

리스트는 동일하지 않은 자료형 항목도 저장함
--> but, numpy는 동일한 자료형만
--> 효율적 접근 가능, 데이터 고속 처리 가능

Numpy 활용의 기본
1) 브로드캐스팅
- 스칼라값을 벡터의 각 원소로 전파하여 덧셈함 --> 복사에 따른 속도 저하 피할 수 있음

2) 인덱싱, 슬라이싱
- python 리스트와 동일한 방식임

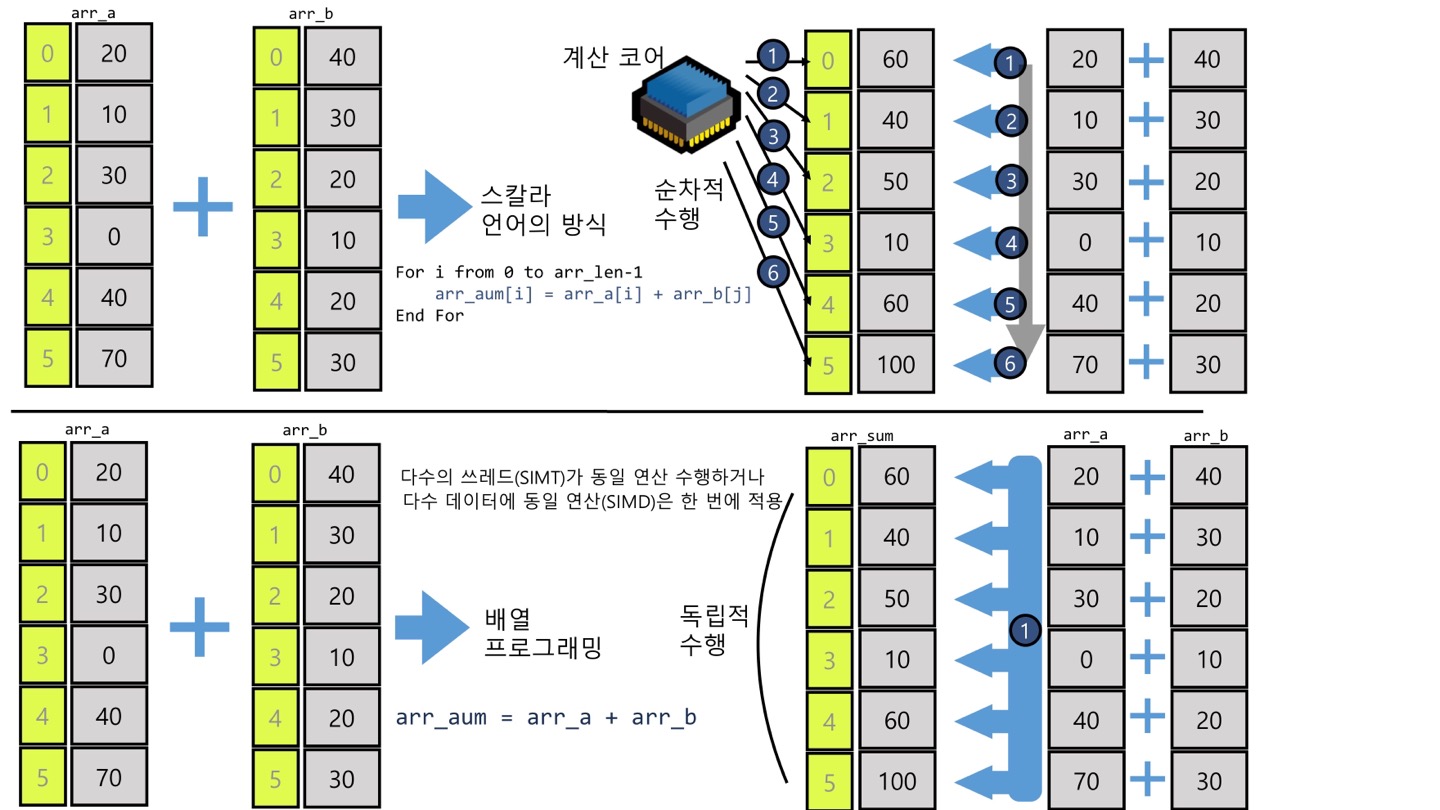
3) 벡터화
- numpy를 이용한 수치 데이터 처리의 가장 큰 장점
- 벡터화 연산은 배열의 원소 각각을 가져와 연산하는 것 X --> 하나의 명령이 여러 데이터에 동시에 적용됨
- 벡터화를 통한 병렬적인 연산: 하나의 프로세서 내에서 병렬적 데이터 처리
(큰 작업 분할하여 다수의 프로세서에서 나누어 처리 X)
- SIMD: Single Instruction Multiple Data
- 배열 프로그래밍의 핵심 요소임

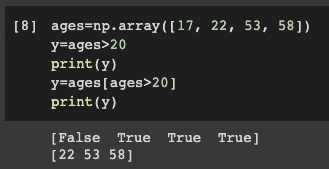
4) 논리 인덱싱
- 어떤 조건을 주어 배열에서 원하는 값을 추려내는 것 --> 배열의 특정한 요소에 접근
'Computer Science > Machine Learning' 카테고리의 다른 글
| [ML] Linear Regression (선형회귀) & Normal Equation (정규방정식) (0) | 2022.04.02 |
|---|---|
| [ML] Pandas 활용 (0) | 2022.03.26 |
| [ML] 과적합 & 과소적합 (0) | 2022.03.26 |
| [ML] Gradient Descent : 경사하강법 (0) | 2022.03.26 |
| [ML] 기계학습에 필요한 수학 기초 지식 (0) | 2022.03.26 |
